
Een onderzoeksproject naar het automatisch met de computer indelen van broodjeaapverhalen, hoe gaat dat eigenlijk? Voor mijn onderzoeksstage met de Volksverhalenbank van het Meertens Instituut heb ik geprobeerd de computer te leren broodjeaapverhalen in verschillende typen in te delen.
Broodjeaapverhalen zijn de oorspronkelijke ‘virale verhalen’. Spannende, vaak enge of afschrikwekkende verhalen die zich verspreiden van mond tot mond (of van emailbox tot emailbox). Het Meertens Instituut heeft ongeveer 3.000 van dit soort verhalen in de Volksverhalenbank. Een goed voorbeeld is “de babysitter en de man boven”, een verhaal waar een babysitter tv kijkt in het huis van een familie waar ze voor oppast. In verschillende versies van het verhaal wordt zij gebeld door een onbekend nummer, waarna ze enge geluiden hoort of de onbekende beller tegen haar zegt dat ze op de kinderen moet letten. Ze belt uiteindelijk de politie, die het nummer natrekt en ontdekt dat de telefoontjes van de bovenverdieping van het huis komen. In verschillende versies van het verhaal worden dan de kinderen op de bovenverdieping vermoord, of wordt zij zelf plots vermoord.
De setting van deze verhalen is altijd modern, en dichtbij: het zou kunnen gebeuren met jou, je zus, of je neef. Ze worden vaak jarenlang doorverteld. Broodjeaapverhalen hoeven niet geheel onwaar te zijn: de details zijn soms geheel of gedeeltelijk echt gebeurd. Wel bevatten ze vaak een sensationele of emotionele kern, met emoties als afschuw, angst, en woede die de boventoon voeren. Er bestaan theorieën dat broodjeaapverhalen een manier zijn voor mensen om de complexe, moderne samenleving te begrijpen, zoals het feit dat je tegenwoordig meer vertrouwen moet hebben in vreemden (die je voedsel bewerken, of waar je mee in een taxi stapt) en in machines en technologie dan wanneer je leeft in een kleine, overzichtelijke gemeenschap waar je iedereen kent. Door het vertellen van broodjeaapverhalen leer je deze onzekerheden misschien wel te verwerken (zie Fine (1980 en 1985), Best & Horiuchi (1985) en Mullen (1972) voor meer over theorieën over broodjeaapverhalen).
Jan Harold Brunvand, een Amerikaanse folklorist, merkte op dat broodjeaapverhalen ook nog andere dingen gemeen hebben. Naast de bovenstaande gemeenschappelijke kenmerken zijn er ook gemeenschappelijke verhaaltypen (Brunvand, 2002). Hij bestudeerde duizenden verhalen, en vond dat zij samenvielen in 10 hoofd-typen (bijvoorbeeld “CAR”, verhalen over auto’s, of “ANIMAL”, verhalen over dieren), met in elk hoofdtype ook een handvol subtypes (“CAR HORROR”), waar vervolgens ook weer specifieke plots in zitten (“De afgerukte hand in de auto”). Die laatste categorieën worden op het Meertens Instituut (en in het verdere wetenschappelijke veld) gebruikt als metadata, en zijn verbonden met het BRUNVAND index nummer. Deze zijn aan de verhaaltypen gekoppeld door het Meertens Instituut (Meder et. al., 2016). Het is namelijk handig en interessant om te weten welke verschillende verhalen tot hetzelfde type behoren. Zo’n indeling kan ook helpen met het vergelijken van verhalen, en het is dus een hulpmiddel om broodjeaapverhalen te analyseren en onderzoeken.
Als er nu een nieuw verhaal binnenkomt op het Meertens Instituut, moet iemand analyseren tot welk specifiek Brunvand index nummer het verhaal behoort. Mensen lezen een verhaal dan uitgebreid door, en gebruiken hun ervaring met eerdere verhalen om te kijken welk verhaaltype er het dichtst bij ligt. Een computermodel kan echter ook verhaaltypen leren indelen, maar doet dit anders. Zo’n computermodel leest het verhaal niet als geheel, maar telt allereerst de woorden en hoe vaak bepaalde woorden in verhalen voorkomen. Het is dus een heel andere manier van “lezen”.
Hoe gaat dit in zijn werk? Allereerst worden alle woorden in een verhaal gestemd. Dat wil zeggen: de woorden “babysitter”, “babysitten” en “babysittende” worden allemaal onder een enkele stam gevoegd: “babysit”. Vervolgens wordt elk woord omgevormd tot een bepaald nummer, waarna het computermodel telt hoe vaak een uniek nummer voorkomt in een bepaalde tekst. In de data staat dan bijvoorbeeld dat “broodjeaapverhaal 1” drie keer het woord “babysit” heeft. Vervolgens kijkt het model naar hoe vaak de woorden in alle documenten voorkomen. Meer unieke woorden zijn belangrijker dan woorden die in elk document voorkomen, want die woorden die maar af en toe voorkomen helpen met het indelen van de documenten. Als een woord overal voorkomt, helpt het niet zo veel met indelen. Deze unieke woorden worden daarom zwaarder meegewogen dan woorden die in elk document voorkomen (zoals “echt gebeurd”, een kreet die in bijna alle broodjeaapverhalen voorkomt). Vervolgens doet het algoritme hetzelfde met segmenten van twee woorden (bigrams) en drie woorden (trigrams): ook die worden geteld.
Uiteindelijk is er dan een dataset waarin de teksten getransformeerd zijn tot een matrix, zoals dat heet, waarin alle woorden uit het vocabulaire een uniek nummer en een unieke frequentiescore hebben. Bij die dataset zit ook alle informatie over welk hoofdtype, subtype, en Brunvand-nummer bij een tekst hoort.
Het algoritme trainen
Daarna komt de fase van trainen. Een machine learning algoritme (in dit geval een standaard type, een Support Vector Machine) krijgt een heleboel voorbeelden van verhalen met informatie welk broodjeaapverhaal-type die verhalen zijn. Al deze voorbeelden gaat het algoritme in een multidimensionale ruimte plaatsen: welke lijken het meest op elkaar? Daarna is er een soort plattegrond van broodjeaapverhalen: de teksten met bepaalde waarden horen bij bepaalde verhaaltypen. Het model ontdekt vervolgens grenzen: waar in deze multidimensionale verhalen zitten “HORROR” verhalen? En waar zitten “ANIMAL” verhalen?
Met dit getrainde model kunnen we vervolgens nieuwe broodjeaapverhalen classificeren. We geven het model een totaal nieuw broodjeaapverhaal, en geven het model de opdracht om er het juiste verhaaltype bij te vinden. Vervolgens kan het model dat razendsnel, en soms beter dan mensen, door het verhaal in die multidimensionale ruimte te plaatsen en te kijken of het dichtbij “HORROR” verhalen ligt, of juist dicht bij “CAR” verhalen.
Voor dit specifieke onderzoek hadden we drie modellen nodig, want tenslotte zijn er drie verschillende soorten typen: hoofdtypen, subtypen, en unieke Brunvand verhaaltypen. Het model is beter in het eerste onderscheid maken, want er zijn tien hoofdtypen die elk vrij veel voorbeelden hebben. Hoe meer voorbeelden het model in de trainingsfase gezien heeft, hoe preciezer de voorspelling wordt.
Dit kan voordelig uitpakken, door te besluiten dat, als het model beter is in het hoofdtype voorspellen, je vervolgens alleen maar de subtypen in dat hoofdtype wil voorspellen. Hierdoor gebruik je de hiërarchie van het model, en buit je uit dat het model beter is in het voorspellen van de grotere klassen. Automatische classificatie van broodjeaapverhalen is wel eerder gedaan (o.a. door Nguyen et. al., 2013), maar nog niet met gebruik van de hiërarchie die inherent in de typologie zit.
Het “domme” algoritme raakt in de war van irrelevante verteldetails
Zoals ik eerder al zei is zo’n model niet per se slim: het werkt niet zoals mensen, die een hele tekst lezen en begrijpen. Dat wil zeggen: de teksten die het model als voorbeelden geeft, worden niet echt door het algoritme begrepen. Er wordt simpelweg geteld. Dit kan voor problemen zorgen als er nuance en ruis in de dataset zit, en in dit geval zat er een grote ruis in: irrelevante tekstuele elementen die niet specifiek zijn voor een bepaald (sub)type broodjeaap-verhaal.
De aanname van het classificatie-model is dat de verschillende unieke verhaaltypen een verschillend en eigen woordgebruik hebben. “CAR” broodjeaapverhalen zullen vooral woorden hebben over auto’s, “ACADEMIC” zullen voornamelijk vol staan met woorden als “school”, “campus” en “universiteit”. Meestal werkt deze simpele aanname erg goed (sommige broodjeaapverhalen worden 80 tot 90 procent van de tijd juist herkend!), maar soms leiden ze ook tot verwarring.
Het Meertens instituut krijgt namelijk broodjeaapverhalen uit verschillende bronnen: interviews, krantenartikelen, en zelfs e-mail. Er zijn in de database dus ook groepen te maken op basis van kenmerken van deze verschillende mondelinge en schriftelijke bronnen. Een interview heeft bijvoorbeeld vaak het woordje “uhm”, en de interviews in de database gaan vaak over dezelfde broodjeaapverhalen omdat dezelfde interviewer er in verschillende interviews naar vraagt. Een voorbeeld kan zijn dat een interviewer in het kader van een project over voedsel meerdere interviews heeft toegevoegd die gaan over verhalen die met voedsel te maken hebben. Het model leert dan van de data dat “uhm” een kenmerk is van voedsel-broodjeaapverhalen, omdat “voedsel” broodjeaapverhalen vaak “uhm” in de tekst hebben. Het model wordt dan een model voor het herkennen van de bron van het verhaal (mondeling interview wordt onderscheiden van krantenartikel, bijvoorbeeld), niet van het herkennen van een type broodjeaapverhaal.
Om dit te voorkomen, moeten we de data schoonmaken. Dat wil zeggen: we moeten ervoor zorgen dat het model niet in de war kan raken door dit soort verwarrende (spreek)taal-elementen.
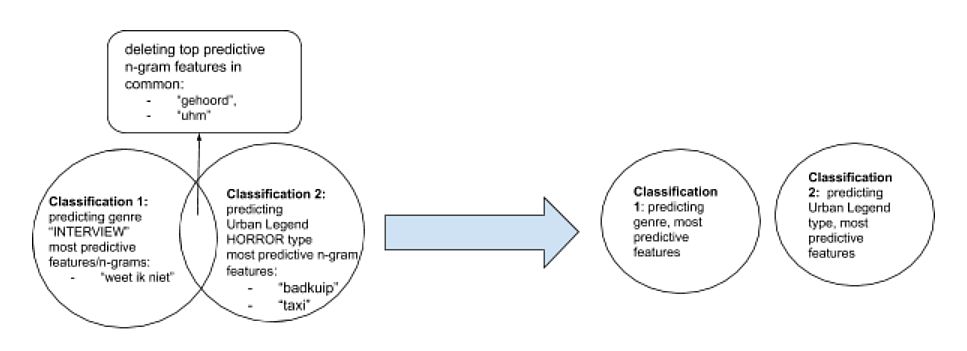
Dit kon door middel van experimenten volgens het bovenstaande diagram. We probeerden te voorspellen welke categorie een broodjeaapverhaal had. Vervolgens probeerden we te voorspellen welke bron een broodjeaapverhaal had, zoals “krant” of “interview”. Als er woorden of groepen woorden waren die essentieel waren voor het voorspellen van het vertelgenre (“kuch”, “kan-ie”, “verslaggever”) die ook voorkwamen in de lijst van woorden waarmee een broodjeaapverhaal-categorie voorspeld was, dan verwijderden we die woorden uit de verhalen. Dit “schoonmaken” leidde er uiteindelijk toe dat het model beter werd in het voorspellen van het broodjeaapverhaaltype zonder het te verwarren met vertelgenre.
Resultaten: (on)gelijkheid van broodjeaapverhaal-typen, en interactieve demo
Uiteindelijk kon na dit schoonmaken een model gemaakt worden dat redelijk de meeste broodjeaapverhalen kan herkennen en indelen, maar de resultaten waren nog niet voor elk type even goed. Zo bleek dat sommige verhaaltypen, zoals “poedel in de magnetron”, bijna perfect herkend werden door het model (een F1 score van .86), en andere verhaaltypen (“toerist horror verhaal”, bijvoorbeeld) heel slecht herkend werden. Waarom was dit zo? We gingen beter kijken naar de verschillende verhalen, en kwamen erachter dat niet elk verhaaltype even “hetzelfde” was. Het verhaal over een oud vrouwtje dat een poedel of ander dier in de magnetron stopt is (vrijwel) altijd hetzelfde en heeft dus ook vrijwel altijd hetzelfde woordgebruik, terwijl verhalen zoals het “toerist horror verhaal” meer in een soort rest-categorie zitten: dit verhaal kan zich vrijwel overal afspelen, met allerlei enge gebeurtenissen, met als enige gemene deler dat er iets ergs met toeristen gebeurt. Het model vond dat (te) lastig om te onderscheiden van andere verhalen, en in één type in te delen.
Een belangrijk punt: hoe kan het niet-perfect werkende model alsnog gebruikt worden voor correcte classificatie? Wederom bleek de hiërarchie essentieel voor de oplossing. We maakten een demo waar 5 test-verhalen in staan. Deze demo was sterk gebaseerd op Brandsen et. al. (2019)’s demo voor de Koninklijke Bibliotheek voor het categoriseren van thesissen.
Het idee van de demo is dat mensen die een verhaaltype willen weten, kunnen kijken welke categorieën het model aanreikt, en kijken of deze correct zijn volgens de metadata in de database. Als de bovenste categorie wel correct is (“CAR”), maar de sub-categorie bijvoorbeeld niet, kunnen mensen het model corrigeren door onderaan de pagina een interactieve boom van broodjeaapverhalen te verkennen. Zij kunnen vervolgens zien welke sub-categorieën er onder “CAR” vallen, en welke verhaaltypen weer onder die sub-categorieën vallen. Zo vullen model en mens elkaar aan om de verhalen toch correct te classificeren, met behulp van de hiërarchie van de verhaaltypen.
Conclusie
Uiteindelijk heeft het onderzoeksproject geleid tot meer inzicht in broodjeaapverhalen, maar niet per se tot een waterdicht automatisch classificatie-model. Zo blijkt dat werken met simpele woord-vectors voor sommige verhaaltypen tot heel goede resultaten kan leiden, waarin het model vrijwel alle verhalen van één type correct kan herkennen, maar dat dit voor andere verhaaltypen niet voldoende is voor herkenning. Een bijkomend ontdekt probleem is dat de bron van het verhaal in de database (zoals “krant” of “interview”), met specifieke vormkenmerken, een verwarrende factor is voor het model, aangezien soms een bron-element herkend wordt als een kenmerk van een verhaaltype. Uiteindelijk was het nodig de data intensief “schoon te maken” van deze tekstuele elementen die voor het model te verwarren waren met inhoudelijke broodjeaapverhaal woorden. We vonden dat het gebruik van de hiërarchie wel essentieel was voor de oplossing: ook menselijke annotatoren kunnen de voorspellingen van het model samen met een interactieve broodjeaapverhaal-boom gebruiken om (alsnog) het juiste verhaaltype bij een verhaal te vinden. Mens en computermodel werken dan samen, met twee soorten van “lezen”, om tot het juiste antwoord te komen.
Referenties & Bronnen
Best, J. and Horiuchi, G. 1985. The Razor Blade in the Apple: The Social Construction of Urban Legends. Social Problems 32(5), 488-499.
Brandsen, A., Kleppe, M., Veldhoen, S., Zijdeman, R., Huurman, H., Vos, H. De, Goes, K., Huang, L., Kim, A., Mesbah, S., Reuver, M., Wang, S., Hendrickx, I. (2019), Brinkeys. KB Lab: The Hague, the Netherlands.
Heel interessant, bedankt voor deze uitleg! Maar komen er bij het Meertens Instituut echt zoveel broodjeaapverhalen binnenn dat automatisering zinvol is? Nog een andere vraag die opkomt: kun je de classificatie ook gebruiken om geautomatiseerd schema’s voor nieuwe verhalen te bedenken? Poedel in de magnetron kun je bijvoorbeeld abstraheren tot huisdier in huishoudelijk apparaat en dan kun je ook siamees in de droger en hamster in de staafmixer vormen.
Ik kan me er niet zo veel herinneren:
– Jong meisje beleeft in Amerika liefdesnacht, denkt romantisch bericht te krijgen, maar dit luidt: ‘Welcome to the AIDS-family’.
– Bij Chinees restaurant in Leiden ontdekte serveerster dat er rat werd bereid.
– Bij shoarmazaak daar om de hoek zou de keuringsdienst in de knoflooksaus sperma van 5 verschillende mannen hebben aangetroffen.
– Een student fietste bewust in de gracht tegenover het stuidentenhuis van een meisje dat hij wilde versieren, om daar voor hulp aan te kunnen bellen.
– Tijdens familievakantie in Spanje gaat oma dood. Om gedoe te voorkomen gaat ze mee in de dakkoffer, maar tijdens een stop bij een wegrestarant wordt de auto gestolen.
Die staan ongetwijfeld allemaal in de Brunvand.
Er zitten ruim 3000 broodjeaapverhalen in de Nederlandse Volksverhalenbank, maar dat zijn deels varianten op dezelfde verhaaltypen. Dat valt natuurlijk ook wel met de hand te classificeren, maar de uitdaging is om te zien of we zoiets kunnen automatiseren. Er zijn bovendien nog meer genres: sprookjes, sagen, legenden, raadsels, moppen, kwispels, personal narratives… en dat ook nog eens in het Nederlands, het Fries, streektalen en dialecten en Middelnederlands en 17e eeuws (momenteel: 46.000 verhalen in de database). Eer dat de computer dat allemaal aan kan, zijn we wel de nodige experimenten verder. Het is goed om te beginnen met een deelprobleem.
Bij een verhaal met een kat in de magnetron spreken we van een variant van hetzelfde type. Er is dus al variatie mogelijk, maar de hamster en de staafmixer is wel erg apart – daar zou een nieuw typenummer voor aangemaakt moeten worden, denk ik. Tenminste… als zo’n verhaal ook echt viraal gaat. Van de 5 broodjeaapverhalen die je je herinnert, zijn er 4 bekende verhaaltypen die ook in de catalogus van Brunvand staan. Die van de student is nieuw voor mij 🙂
Wat leuk dat het artikel en de uitleg leuk gevonden wordt!
Generatie van nieuwe broodjeaapverhalen zou misschien mogelijk zijn, maar dat is een heel ander soort experiment dan al bestaande broodjeaapverhalen classificeren. Dan kun je je bovendien gaan afvragen hoeveel “variatie” er in die nieuwe verhalen kan of mag zitten, en wanneer iets nog onder één type valt.. Kortom: misschien een leuk vraagstuk voor een vervolg-experiment!
Ik vroeg me af hoe de indeling (en de classificatie-automatisering) omgaat met overlappende categorieën. Zo zal ACADEMIC ongetwijfeld in meerdere gevallen overlappen met andere categorieën, zoals ANIMAL (de vermoorde meisjes op de campus blijken het slachtoffer van de enorme ratten uit de uiteraard niet te schone keuken – ik noem maar wat).
Verder: erg interessant! (Al vind ik ‘broodje-aap’ altijd een wat knulliger woord dan ‘urban legend’ 🙂 )
Wat leuk dat het artikel leuk gevonden wordt! 🙂
Het idee was dat de hierarchie dit zou oplossen: als een verhaal al in model 1 als “ANIMAL” geclassificeerd was, kon er geen sub-type buiten die hoofdcategorie geselecteerd worden (bijv. een sub-type over dieren in HORROR). Helaas kan dit ook zorgen voor fouten soms: als het model dan een verkeerd hoofdtype kiest, gaat het meteen al de mist in.
Ook is het vaak zo dat de simpele aanname “hetzelfde soort woorden worden gebruikt in dezelfde categorieeën” vaak werkt. De verhalen in de ANIMAL groep hebben, om het simpel te zeggen, overwegend “dier” woorden, terwijl bijvoorbeeld een subcategorie van HORROR groep, “animal horror”, allereerst overwegend “horror-woorden” heeft, met een “vleugje” dier. Dit is de aanname van de typologie en ook van het model, en het model leert in de trainingsfase uiteindelijk vrij precies waar precies de “DIER HORROR” verhalen in de multidimensionele ruimte zitten, en waar de “HORROR” verhalen zitten.
Maar zoals gezegd: voor sommige verhaaltypes werkt zo’n aanname heel erg goed, voor andere verhaaltypes niet. Verhalen in het echte leven zijn “rommelig” en gedragen zich misschien niet precies zoals andere verhalen in hun categorie. Dat maakt het zo leuk om met zulke tekstdata en computermodellen te werken, je komt veel te weten over hoe de teksten en de modellen nou eigenlijk “werken”.
Brunvand is wat dat betreft eigenzinnig te werk gegaan: op basis van zijn eigen bloemlezingen heeft hij de categorieën, subcategorieën en verhaaltypen bedacht. Overlappingen worden zoveel mogelijk vermeden, en bij vermenging kan een verhaal desnoods twee typenummers krijgen bijvoorbeeld – maar dat gebeurt niet vaak.
Het begrip Broodje Aap hebben we te danken aan het eerste boek van Ethel Portnoy dat in Nederland aandacht besteedde aan het genre. Sindsdien zitten we ermee, en de meeste Nederlanders kunnen zich er het nodige bij voorstellen. Internationaal spreken de specialisten het liefst van ‘contemporary legends’. Immers, ‘urban’ is ook misleidend: de verhalen zijn evengoed bekend op het platteland.