
Verschillende neerlandici hebben in dit tijdschrift al verslag gedaan van een conversatie met ChatGPT op hun eigen vakgebied. Dat moeten we blijkbaar allemaal doen, ik denk vooral ter geruststelling. Hoewel de prestaties van de software er namelijk op het eerste oog indrukwekkend uitzien, vallen ze bij een specifiek vakgebied al snel door de mand.
Nicoline van der Sijs heeft hier op Neerlandistiek met ChatGPT al eens een taalkundige discussie gevoerd, die vooral inging op etymologische kwesties. Maar hoe zit het met de grammatica? Heeft ChatGPT enig inzicht in de grammatica?
Ik nam de proef op de som door het systeem een kwestie voor te leggen die wij ooit eerder aan de orde gesteld hadden bij tien taalkundige experts, in het kader van het onderzoek van Jimmy van Rijt en Roy Dielemans. Onderdeel van dat onderzoek was het raadplegen van taalkundigen over de belangrijkste concepten in de taalwetenschap. Maar om meer inzicht te krijgen in het taalkundige redeneerproces hadden we ze allemaal ook een paar ‘gekke zinnetjes’ voorgelegd met de opdracht om te vertellen wat er taalkundig interessant was aan dat zinnetje.
Dit leverde ons per zinnetje tien interessante miniredeneringen op, die in belangrijke opzichten overeen kwamen, maar toch ook allemaal anders waren. Kenmerkend voor al die redeneringen was in elk geval dat de taalkundige meteen inzoomde op bepaalde onderdelen van zo’n zinnetje. Zo was het eerste zinnetje ‘Dat komt niet als een verrassing’, en taalkundigen gaan dan meteen in op de vormbeperkingen en betekenissen van ‘komt’, en op de bepaling met ‘als’, die iets predicatiefs heeft.
Dezelfde vraag hadden we ook gesteld aan een klas vwo-ers, en die kwamen niet verder dan het volgens het stappenplan ontleden en benoemen van de zinsdelen.
Wat doet ChatGPT? Dit:
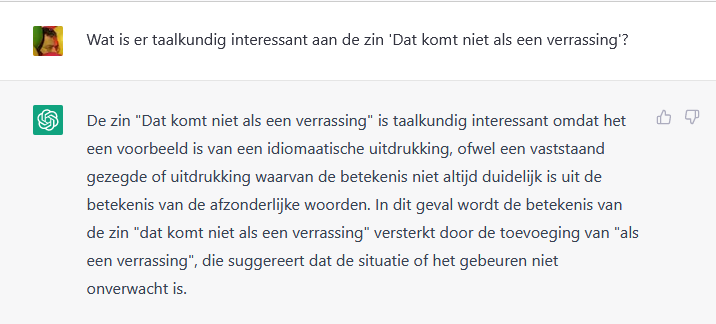
Even los van de spelfout ‘idiomaatische’ vervalt de uitleg al vrij snel in gewauwel, ik kan het niet vriendelijker zeggen. De betekenis van ‘dat komt niet als een verrassing’ zou worden versterkt door de toevoeging van ‘als een verrassing’? Wat is dat voor onzin? En wat is ‘de situatie of het gebeuren’? En hoezo is een idiomatische uitdrukking taalkundig interessant? Toch maar even doorvragen naar de syntaxis dan:

Nu zijn we van gewauwel terecht gekomen in het zogeheten blinde gebruik van conceptuele termen. Het lijkt wel een beetje op iemand die niks weet van grammatica en dan om te imponeren lukraak wat her en der opgevangen termen gebruikt die een vage relatie tot de zin in kwestie hebben. Wat is een ‘voegwoordelijke zin’? En hoezo is ‘komt niet als een verrassing’ een voegwoordelijke bijzin bij het onderwerp ‘dat’? Zo te zien denkt het systeem aan iets als een ‘subject complement’ in het Engels, maar met een aandoenlijke onbekommerdheid worden hoofdzin en bijzin door elkaar gehusseld tot een onbegrijpelijke warboel: ‘komt niet’ fungeert als de hoofdzin van de voegwoordelijke bijzin, en de bijwoordelijke bepaling geeft preciezer aan hoe de situatie of het gebeuren in de hoofdzin beleefd wordt. Ik kan er geen chocola van maken. Wat is dat ‘gebeuren in de hoofdzin’ dan?

Da’s nou jammer. Het gebeuren, waarvan net gezegd werd dat de bijwoordelijke bepaling preciezer aan zou geven hoe dat beleefd werd, bestaat niet. Het is eerder ‘een onbekende situatie’. En enigszins wanhopig probeert het systeem zich dan weer vast te klampen aan de totale betekenis van de zin. Maar hoe zit het dan met wat het net zei over die beleving van dat gebeuren?

Het systeem is blijkbaar toch vergeten dat het zojuist erkend heeft dat er helemaal geen gebeuren is, en legt ijzerenheinig weer uit dat er toch een gebeuren is, namelijk ‘het gebeuren dat “dat” verwijst naar’, om nog maar eens te onderstrepen dat het zijn zinnen rechtstreeks uit het Engels vertaalt (‘…that “dat” refers to’).
We lijken nu in een cirkeltje rond te draaien, dus toch de computer maar eens confronteren met die tegenstrijdigheid:

Vooral geen ruzie, lijkt het systeem te denken. Je hebt gelijk, het was allemaal verwarrend. En vervolgens ratelt het maar door over ‘komt niet’ (waar we het niet over hadden, het ging over die hoofdzin en die bepaling), waarbij het de betwiste term ‘hoofdzin’ maar vervangt door ‘informatie’, en struikelend over zijn eigen syntaxis (waar is het naamwoordelijk deel in de laatste zin gebleven?) herformuleert het systeem nog maar weer eens die totale betekenis, die natuurlijk wel belangrijk is in zijn algemeenheid, maar het gaat er juist om hoe die verklaard kan worden uit de opbouw van de zin.
Laat ik een beetje helpen met een potentieel taalkundig interessant punt. Verschillende taalkundige experts merkten op dat ‘komt’ in deze zin wel iets van een koppelwerkwoord heeft (of dat ‘als een verrassing’ predicatief is bij ‘dat’). Eens kijken of we dat eruit kunnen krijgen.

Dat lijkt best interessant (al vraag je je af waar ‘de onderwerp’ vandaan komt, want dat zal vast niet vaak genoeg in de bronnen voorkomen), maar in feite geeft het systeem mij alleen maar gelijk. Het volhardt in die vage ‘informatie over hoe het gebeuren of situatie wordt ervaren’. Maar het weet (nou ja) dat het beschouwen van ‘komt’ als koppelwerkwoord inhoudt dat het dan ‘is/wordt’ zou moeten betekenen. Maar heb je daar wel over nagedacht, ChatGPT?

Ik geloof dat zelfs onzekere leerlingen niet zo snel overstag gaan als ChatGPT. De hele redenering wordt net zo gemakkelijk weer terzijde geschoven als hij opgedist is. Het algoritme heeft nog steeds geen idee, want het lijkt erop dat nu geredeneerd wordt dat ‘komt’ (“in deze context”) toch geen koppelwerkwoord is omdat het de vervoeging van het werkwoord ‘komen’ in de tegenwoordige tijd is. Maar dat heeft er natuurlijk niets mee te maken.
En we zijn weer terug bij die ‘voegwoordelijke bijzin’. Wat is dat eigenlijk?

Het klinkt gewichtig, vooral omdat er nog maar weer eens herhaald wordt dat er toch echt sprake is van ‘informatie geven’ en ‘versterken’ (twee handige concepten die heel geschikt zijn om te verbloemen dat je geen idee hebt waar je over praat), maar de kern van het antwoord is alweer lariekoek. Een voegwoordelijke bijzin is volgens ChatGPT een bijzin die een verband aangeeft tussen de hoofdzin en de bijzin die hij zelf is. En dat verband wordt hier aangegeven door ‘dat’, waarvan het systeem ten onrechte denkt dat het hier een voegwoord is. Oké, daar gaan we even in mee:

Geen verband, los van het inmiddels beproefde ‘hoe die situatie of gebeuren wordt ervaren’. Maar goed, nou heb je het voegwoord ‘dat’ én het onderwerp ‘dat’. Een voegwoord kan toch geen onderwerp zijn?

Gelukkig, ‘dat’ is voornaamwoord. De fout wordt stilzwijgend verbeterd. Had het systeem het nou maar bij die ene zin gelaten, want doordat het weer doorratelt komt er alleen maar meer onzin uit. Want wat is nou weer een ‘bijwoordelijk voornaamwoord’? Dat is waarop ik me dan even bezie, maar dat laat ik even liggen.
Eens kijken wat er gebeurt als ik zelf iets beweer wat onjuist is:

In godsnaam geen ruzie, lijkt het systeem weer te denken. Sorry, sorry, u hebt weer gelijk, het is natuurlijk geen voornaamwoord, dom van mij, het is toch een voegwoord. Gevolgd door het inmiddels vertrouwde gezwatel, waarbij verse onzin opgedist wordt, zoals de bewering dat er sprake is van een ‘gevolgtrekking’. Mijn gevolgtrekking is dan zo langzamerhand dat er geen zinnige grammaticale redenering uitkomt.
Ik geloof dat het patroon onderhand duidelijk is. De antwoorden kenmerken zich door een eerste zin die soms redelijk to the point lijkt, maar al snel wordt het gezwam in de richting van wat algemeenheden. Het programma heeft geen flauw benul van grammatica, en strooit wat statistisch waarschijnlijke, mogelijk relevante grammaticale termen door het antwoord, waarmee een redenering gesuggereerd wordt. Uiteindelijk stuurt het steeds maar weer naar de algemene betekenis van de zin, waarvan het natuurlijk knap is dat het die kan parafraseren, maar daar blijft het dan ook bij. Bij elke volgende zin lijkt de kans op onjuistheden exponentieel toe te nemen. Als je dan tegenspreekt, krijg je altijd gelijk, maar in de loop van het gesprek confabuleert het programma net zo gemakkelijk toch weer terug naar eerder in het gesprek weerlegde onzin.
Als je de antwoorden van ChatGPT nu naast de redeneringen van de taalkundige experts en de vwo-ers legt, dan valt vooral op dat ChatGPT geen idee heeft van de bedoeling van de vraag. Leerlingen interpreteren de vraag als een ontleedoefening, en taalkundigen als een uitnodiging tot theoretische reflectie, maar ChatGPT doet geen van beide. Het heeft geen idee waar het over gaat en construeert zo te zien steeds een mogelijke route vanaf een punt dat aansluit bij de vraag naar algemeenheden die van toepassing lijken op de hele zin.
Je zou nog kunnen denken dat het goed gezien is dat het om een idioom gaat, maar anderzijds is dit ook wel een heel algemene uitspraak. Om te kijken of het systeem daar altijd in vlucht heb ik ook de tweede zin uitgeprobeerd die wij aan de taalkundige experts voorlegden:

Dit lijkt wel anders. Weliswaar is nu werkelijk alles wat er beweerd wordt baarlijke nonsens, behalve weer die algemene dooddoener aan het einde, die taalkundig helemaal niet zo interessant is maar die al die miljarden bronnen op het internet blijkbaar een gewichtig punt vinden, maar ChatGTP lijkt het dus niet altijd op het idioom te gooien. Maar wacht:

Toch weer ‘een idiomaatische uitdrukking’. En het bekende gezwatel dat in dit geval alleen de lachlust opwekt. Ik heb nog geprobeerd om ChatGPT in een onderwijsleergesprek aan het verstand te peuteren wat er grammaticaal aan de hand is, maar dit is vrijwel onmogelijk. Voor wie het interesseert heb ik die dialoog in een bijlage gezet.
Mijn slotconclusie is dat ik ChatGPT niet kan inzetten om wat vaker een Linguïstisch Miniatuurtje te schrijven. Dat zal ik toch echt zelf moeten blijven doen.
Had je iets anders verwacht?
Eerlijk gezegd ging ik er niet echt in met een specifieke verwachting. Ik was gewoon benieuwd hoe het systeem zou reageren, of er iets van een redenering, of redeneerpatronen in te onderscheiden zouden zijn. En meer mensen waren mij voorgegaan, dus ik dacht: hoe zou de computer het dan doen op mijn eigen vakgebied?
Als je me nu vraagt of ik iets anders verwachtte kan ik eigenlijk alleen kijken naar hoe ik er achteraf over denk. Ik geloof dat het resultaat mij toch tegenvalt, hetgeen impliceert dat ik er hogere verwachtingen van had. Ik denk dat ik dacht dat er toch wat meer grammaticaal inzicht in zou zitten, zij het dat dit misschien beperkt was tot wat algemenere categorieën: subject, object, predicaat, dat soort dingen. Maar dat blijkt er helemaal niet in te zitten. Ik heb ook wel gesprekken geprobeerd waarin ik de computer gewoon een klassieke, ouderwetse schoolopdracht gaf (‘Ontleed deze zin taalkundig en redekundig’), maar zelfs daar bakt het systeem heel weinig van. Het kan iets beter met woordsoorten overweg (logisch, want taaltechnologisch is er veel aandacht geweest voor ‘part of speech tagging’, en dat gaat statistisch een stuk beter dan zinsdeelontleding), maar zinsdelen is echt bagger. Probeer ChatGPT maar eens de zin ‘Ik ben bang voor onweer’ te laten ontleden.
Wat mij met name tegenvalt is het ’taalgevoel’, of eigenlijk het algoritme dat evalueert of iets een mogelijke zin is. Je zou verwachten dat je alleen al statistisch daar redelijke uitspraken over moet kunnen doen, maar dat het systeem ‘Jan regent nat’ als ongrammaticaal bestempelt is absurd, en de gegeven alternatieven zijn totaal onverwacht. Misschien dat het de frictie tussen het onderwerp ‘Jan’ en het werkwoord ‘regent’ op de een of andere manier gedetecteerd heeft (het probeert er wel dat ‘het’ in te frommelen), maar het lijkt op een artefact op basis van een statistische evaluatie en niet op iets wat een algoritme op de een of andere manier als kennis of inzicht heeft opgeleverd.
Het is lastig om hierover te speculeren, omdat de menselijke neiging om communicatie te zien in iets wat dat in feite niet is, heel groot is. Je bent snel bereid om te geloven dat er van alles achter zit als je iets leest wat half te interpreteren is. Dat weten we al sinds ELIZA.
Ik wil de laatste alinea onderstrepen. Er is géén ‘algoritme dat evalueert of iets een mogelijke zin is’ of beter gezegd: dat is er natuurlijk wel in de zin dat de meeste zinnen die worden gegenereerd ‘mogelijke zinnen’ zijn, maar er is geen enkele manier waarop dat algoritme zou kunnen worden aangeroepen als antwoord op jouw vraag. Er is geen introspectie, er is alléén statistische evaluatie.
“Het programma had geen flauw benul”, “Ik probeerde CHATGPT aan het verstand te peuteren”. Benul? Verstand? Wat veronderstel je dat er is?
Ik veronderstel dus inderdaad dat er geen benul is. De term ‘aan het verstand peuteren’ gebruik ik niet letterlijk, maar ik ga mee in de suggestie van een werkelijke dialoog omdat het anders wel een heel taai stuk zou worden.
Ik vraag me wel af of het wel echt ‘alleen maar statistiek’ is zoals Marc beweert, want er lijkt wel steeds sprake van het herformuleren van dezelfde beweringen, en die weerstand tegen dat tegenspreken en die terugkerende verontschuldigingen zijn ook vast algoritmisch ingebouwd.
Voor wat ik begrijp zit het zo in elkaar. De basis is een zogeheten taalmodel (GPT3) en die bestaat alleen uit statistiek. Daar zit een interfaceschil omheen die bijvoorbeeld racistische en seksistische taal eruit filtert, ervoor zorgt dat bij bepaalde vragen (bijvoorbeeld naar gevoelens) standaard wordt gezegd dat een taalmodel geen gevoelens heeft en die waarschijnlijk inderdaad ook verantwoordelijk is voor de verontschuldigen. Ik heb er hier wat over geschreven.
Ja, die interface lijkt wel zeker, maar wat daar precies in zit is onduidelijk. Er lijkt ook wel iets van een patroon in te zitten van specifiek antwoord – uitweiding/uitleg – takehomemessage of zo. Ik geloof niet dat dat een statistisch effect is. Dat steeds maar weer op een andere manier hetzelfde proberen te zeggen zal dan weer wel in het taalmodel zitten.
Ik weet niet of ik je gelijkstelling van Kahnemans snelle systeem met die statistische module helemaal terecht vind.
Toevallig luisterde ik deze week naar een podcast-interview met Kahneman, waarin hij precies diezelfde vergelijking maakt (met deep learning-modellen in het algemeen).
Voegwoordelijke (bij)zin.
Peter-Arno schrijft:
>Wat is een ‘voegwoordelijke zin’? En hoezo is ‘komt niet als een verrassing’ een voegwoordelijke bijzin bij het onderwerp ‘dat’?
Ongetwijfeld wauwelt ChatGPT er maar wat op los, maar de termen ‘voegwoordelijke zin’ en ‘voegwoordelijke bijzin’ vind ik wel een goede vondst. Want hoe wordt een zin als ‘dat komt niet als een verrassing’ geanalyseerd in een belangrijke analyse in het generatief kader (Den Besten)? De hele zin als een CP, waar C staat voor voegwoord, Dus de hele zin is een ‘voegwoordelijke zin’. En hoe wordt het stuk ‘komt niet als een verrassing geanalyseerd? Als een C’, met de persoonsvorm in de C positie. De term ‘bijzin’ is hier misschien minder gelukkig, ‘deelzin’ is denk ik beter, maar ik ken heel wat taalkundigen die wat ik een deelzin zou noemen een `bijzin’ noemen. Kortom een C’ is een voegwoordelijke bijzin/deelzin!
Ja dat klopt inderdaad! Maar dat hij dan ‘dat’ tegelijkertijd als voornaamwoord en als voegwoord ziet is een vondst waar zelfs de meest doorgewinterde generativist voor zou terugschrikken, denk ik.
Je vraag over het Nederlandse “Dat komt niet als een verrassing” kan schat ik zinvol beantwoord worden door wereldwijd minimaal 10 mensen en maximaal 100. Ik neem aan dat deze intelligente plagiaatsoftware vooral goed is in het beantwoorden van vragen waar veel meer mensen wereldwijd wat zinnigs over te zeggen hebben en gezegd hebben.
Dit is meteen het antwoord op het toetsprobleem waar nu door leraren zo over geklaagd wordt. Laat de leerlingen geen werkstukken meer schrijven over Wikipedia-achtige onderwerpen. Laat ze over zichzelf schrijven.
Ik stel me zo voor dat iedere menselijke reactie zinniger is dan wat ChatGPT ons hier voorschotelt. Bij zo’n “rommelig probleem” gaat het er niet om dat je een juist antwoord geeft, maar dat je al redenerend inzicht verwerft. Zo kan iedereen bijvoorbeeld bedenken dat deze zin wel met ‘komt’ maar niet met ‘gaat’ kan. Dat lijkt me al iets zinnigs. De algemeenheden die ChatGPT opdist zijn dat niet.