Voornamendrift (2)
door Gerrit Bloothooft
Onze voornaam behoort tot het privédomein en in veel landen zijn gegevens daarover niet of beperkt beschikbaar voor onderzoek. In Nederland is het sinds 2000 voor wetenschappelijke instellingen bij wet mogelijk om gegevens uit de Basisregistratie Personen (BRP, eerder de Gemeentelijke Basisadministratie, GBA) op te vragen. Dat betekent dat we ten opzichte van andere talen in de uitzonderlijke situatie zitten dat de voornaamkeuze over meer dan een eeuw tot in alle detail te analyseren is. En dat is nodig om het proces van opkomst en teloorgang van voornamen te begrijpen.
Om de mogelijkheden en beperkingen van naamanalyses te overzien geef ik hier eerst meer achtergrond van de beschikbare gegevens. Het gaat om de complete voornaam, geboortejaar en geboorteplaats/land van iedereen die de Nederlandse nationaliteit heeft, in Nederland is geboren en/of in Nederland woont. Alleen degenen die in of na 1994 (het jaar van digitalisatie van de GBA) leefden staan met een persoonsrecord in onze bevolkingsregistratie. De volledigheid van de kennis van de bevolking neemt daarom af wanneer we teruggaan in de tijd. Dat wordt duidelijk als we de ons beschikbare geboorteaantallen uit de GBA vergelijken met het werkelijke aantal zoals dat door het CBS gegeven worden (figuur 1). Maar in het persoonsrecord staan ook de gegevens van ouders. Die hebben we voor zover mogelijk gereconstrueerd, waardoor we een generatie verder terug komen in de tijd, met een start rond 1860. Rond 1880 hebben we al de beschikking over 1/3 van het aantal geboorten, en we vinden dat percentage hoog genoeg om de populariteit van voornamen te presenteren. En zo wordt die ook in de Nederlandse Voornamenbank getoond. We zullen er in analyses wel altijd rekening mee moeten houden dat oudere gegevens niet compleet zijn. Het is dan bijvoorbeeld niet zeker dat een nieuwe naam ook werkelijk nieuw was.
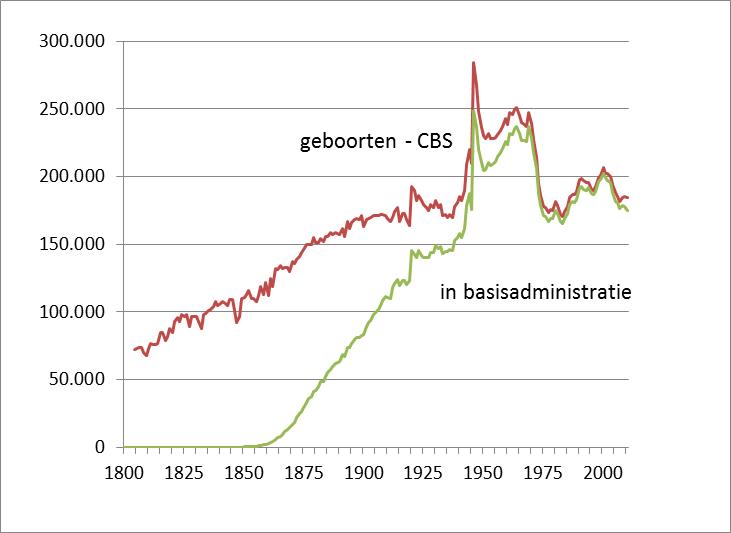
In recente jaren zijn de geboorteaantallen van het CBS en van ons niet helemaal gelijk. Dat komt omdat het CBS alle geboorten van inwoners in Nederland telt, en wij ook de Nederlandse nationaliteit vereisen. Verder valt op dat het aantal geborenen in de 20e eeuw vrij stabiel rond de 170.000 per jaar schommelt, met de babyboom na de Tweede Wereldoorlog gevolgd door hogere geboorteaantallen tot ongeveer 1970. Het vrij constante aantal jaarlijkse geborenen laat zich verklaren omdat het gemiddeld aantal kinderen per vrouw afnam van 4.4 naar 1.7 terwijl anderzijds de bevolking groeide van 5 naar 17 miljoen. De mogelijkheden voor naamkeuzen van kinderen in een gezin verminderden dus sterk in de 20e eeuw.
Naamgegevens zijn privacy gevoelig. De algemene regel is dat een individu niet uit gepresenteerde gegevens afleidbaar mag zijn. Dat risico is het grootst bij lage frequenties want een unieke naam verwijst direct naar de naamdrager. Internationaal wordt daarom de regel gehanteerd dat frequenties lager dan 5 niet getoond worden (of worden die namen niet eens beschikbaar gesteld voor onderzoek). En dat doe ik in deze serie ook niet. Maar omdat we voor Nederland het precieze aantal wel kennen, kunnen op geaggregeerd niveau toch de eigenschappen van zeldzame namen gepresenteerd worden, en dat is nodig om te begrijpen hoe nieuwe namen ontstaan. Voorbeelden van unieke voornamen geven kan echter alleen voor namen die meer dan 100 jaar geleden gegeven zijn. Want dat is de wettelijke grens waarvoor geboortegegevens uit de burgerlijke stand publiek zijn.
Terzijde is het nog opmerkelijk dat het geheugen van onze landelijke, digitale bevolkingsadministratie snel kleiner wordt naarmate we teruggaan in de tijd. Het verschil tussen de rode en groene curve in figuur 1 is wel te vullen, maar vereist een gecoördineerde inspanning om een Historische Basisregistratie Personen (hBRP) te realiseren. Voor veel wetenschappen, niet alleen de naamkundige, zou dat erg waardevol zijn.
Laat een reactie achter