Door Ewoud Sanders
GIsteren bood ik in Neerlandistiek studenten en onderzoekers voor thuisgebruik drie databestanden aan: romans, streekromans en zondagsschoolboekjes. Vandaag zal ik stapsgewijs uitleggen hoe je zo’n dataset met een indexeringstool kunt doorzoeken. Beetje saai om te lezen wellicht, maar wie dit volgt beschikt binnen een uurtje over een fantastisch onderzoeksinstrument.
Er bestaan verschillende indexeringstools, voor Mac en Windows. Zelf gebruik ik dtSearch (‘dtSearch Desktop with Spider’). Die kost eenmalig 199 dollar (€184), maar je kunt gratis een testversie downloaden.
Je kunt er allerlei bestandstypen mee doorzoeken: pdf, Word, txt-bestanden en Excel. Je bouwt als het ware je eigen zoekmachine op één of meer mappen op je pc of laptop. Ter geruststelling: je hoeft hier geen computernerd voor te zijn, dat ben ik zelf ook niet.
Goed, hier de stappen.
1. Download de testversie van dtSearch Desktop with Spider.
2. Zet de documenten die je slim wilt kunnen doorzoeken in een map op je pc of laptop.
3. Open dtSearch, ga linksboven naar de optie Index / Create Index.
4. Geef de index een naam, bijvoorbeeld TEST1 en klik op OK.

5. Klik in dit scherm op JA.

6. Klik nu op Add Folder en navigeer naar de map op je pc of laptop met de bestanden die je wilt indexeren.

7. Nadat je die map hebt geselecteerd klik je op OK en daarna op Start Indexing.

Dat indexeren gaat razendsnel. Voorbeeld: het maken van een index op de map ‘Romans 1940-1945’, met daarin ruim zeshonderd bestanden en 442.242 verschillende woorden, is in vier minuten gepiept.

Nu kun je alle bestanden in die map tegelijk doorzoeken (door op het symbooltje van de loep links bovenaan te klikken).

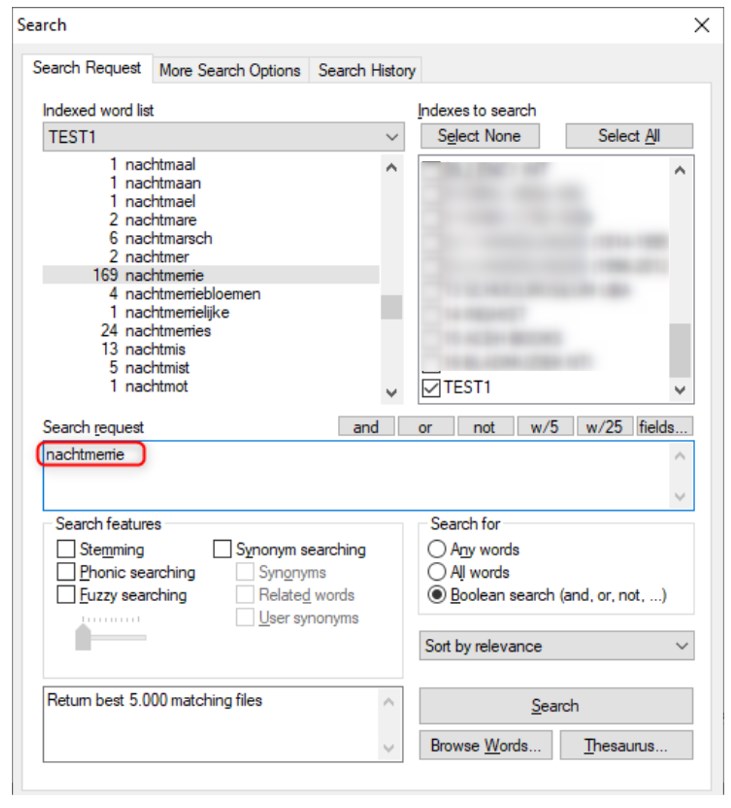
Een groot voordeel van dtSearch vind ik dat je in de index kunt kijken. Als ik bijvoorbeeld nachtmerrie intik, krijg ik dit te zien:
Dus: ik zie niet alleen hoe vaak het woord nachtmerrie voorkomt in deze bestanden (namelijk 169 keer), maar meteen ook deze woordvormen: nachtmerriebloemen, nachtmerrielijke en nachtmerries. Je kunt bij een zoekopdracht woorden trunceren (afbreken) met één of meer sterretjes. Bijvoorbeeld: *nachtmerrie, nachtmerrie* of nach*merrie*. NB zo’n truncatie aan de voorzijde van een woord kan bijvoorbeeld niet in Delpher. Met een dergelijke zoekopdracht kun je allerlei onverwachte woordvormen vinden.
Met een zoekopdracht als “houd je *” vind je zinnen als houd je mond, houd je taai en houd je tof. Je kunt ook woord weglaten: dit wel, maar dat niet (zie de knoppen and, or, not).
Ook erg fijn en praktisch: je kunt woorden in elkaars nabijheid zoeken. Met een zoekopdracht als joden w/10 radio (lees: joden maximaal tien posities verwijderd van radio) vind je een zin als: ‘Het waren de Joden in Engeland, die door de radio het volk ophitsten en het land met valsche berichten overstroomden.’
In de datasets die ik beschikbaar heb gesteld, begint ieder bestand met een jaartal. Daardoor kun je deze bronnen chronologisch of omgekeerd chronologisch sorteren. Standaard worden ze op frequentie gesorteerd. Voorbeeld: in welk van deze bronnen komt het woord laars het vaakst voor? Dat zie je meteen:

Je kunt meteen doorklikken naar de volgende hit binnen een document of naar het volgende document. In het document is het woord gehighlight; daardoor zie je dus meteen de context. Een voorbeeld:

Om die highlights te kunnen zien moet je wel eerst deze plug-in downloaden bij dtSearch. Het installeren wijst zichzelf.
Voor de goede orde: ik weet dat er veel geavanceerdere tools bestaan voor de e-humanities. Die kun je natuurlijk ook loslaten op dergelijke bestanden. Zelf geef ik de voorkeur aan zo’n indexeringstool omdat die zo laagdrempelig is: relatief goed betaalbaar, wordt regelmatig bijgewerkt, makkelijk te installeren en eenvoudig te bedienen.
Voor wie ermee gaat werken: succes en plezier!
Laat een reactie achter