Hoe maken we klanken? Hoe zeggen we een woord als kat? Misschien wel de eenvoudigste gedachte, en een gedachte die zeker tot het begin van deze eeuw ook de beste taalkundige papieren had, is ongeveer: eerst zeg je een K, dan zeg je een A en tot slot zeg je een T.
Dat impliceert dat je ergens in je geheugen hebt opgeslagen hoe je indviduele medeklinkers en klinkers zegt. Praten is dan die verschillende instructies na elkaar uitvoeren, over een alfabet van een beperkt aantal klinkers en medeklinkers, die je vermoedelijk leert als je je moedertaal leert.
Rond de millenniumwisseling begonnen mensen aan dit op het oog zo voor de hand liggende – maar eigenlijk ook wel opvallend op het alfabetisch schrift gebaseerd lijkende – model te twijfelen. Er kwamen allerlei feiten naar boven die erop leken te wijzen dat het anders werkt. Zo blijkt dat mensen klanken een beetje anders maken als ze voorkomen in hoogfrequente woorden (de, man, is) dan in laagfrequente (desolaat, manoeuvre, isagogisch). Dat suggereert dat je de uitspraak van woorden op de een of andere manier als geheel opslaat, en daar ook nog informatie bij onthoudt over hoe frequent ze zijn.
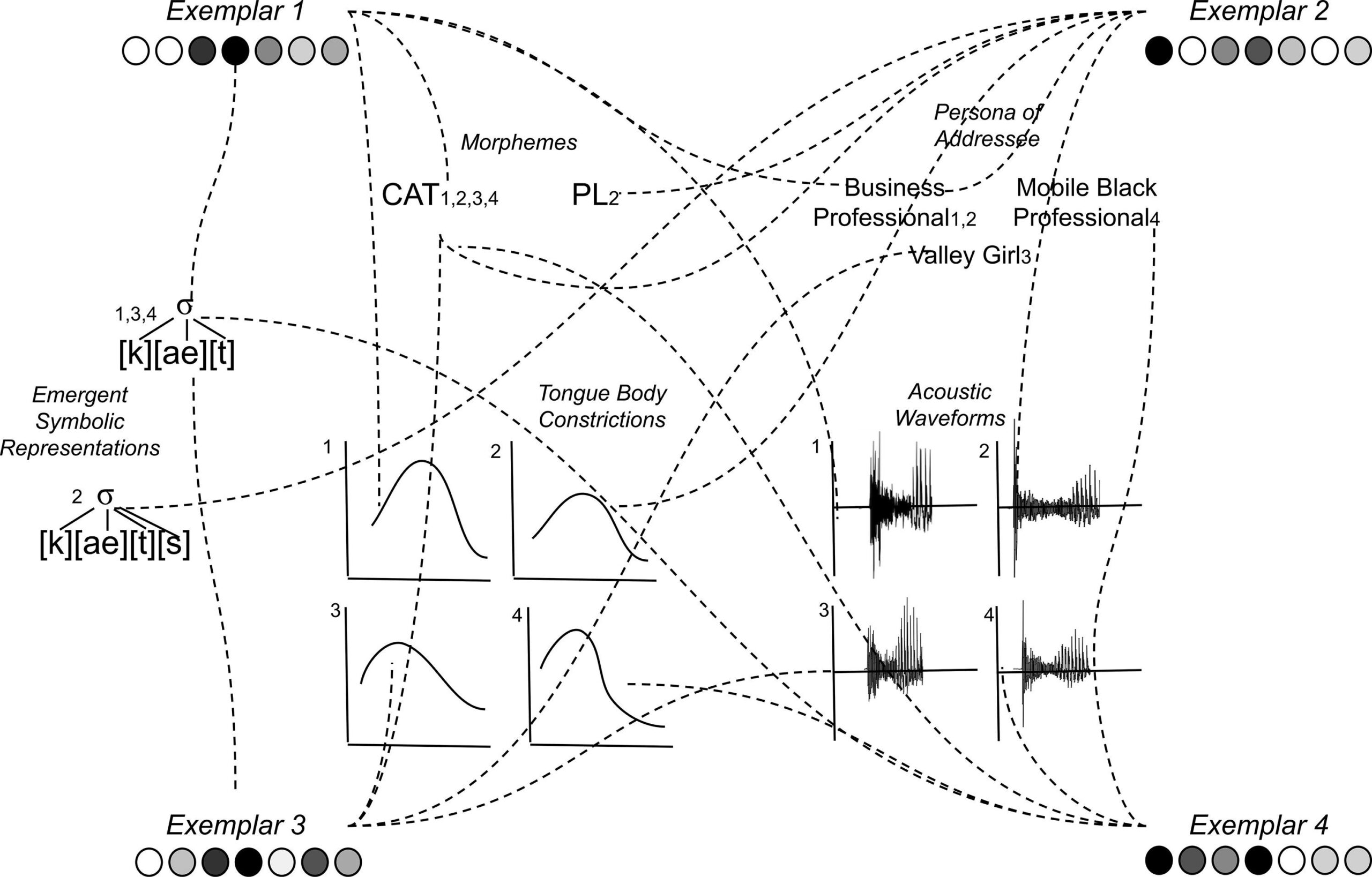
Het model dat zo geboren werd, heet exemplar model: mensen slaan alle instanties (exemplars) op van ieder woord dat ze horen. Altijd als iemand kat zegt, onthoud je hoe dat klonk. Bij het spreken produceer je daar een gemiddelde van. (Ik doe hier even net alsof het over woorden gaat, maar het gaat waarschijnlijk over grotere brokken taal.)
In het Journal of Phonetics staat een artikel van twee bekende vertegenwoordigers van de exemplar theory, Matt Goldrick en Jennifer Cole, die het allemaal keurig op een rijtje zetten: wat was de oorspronkelijke ‘abstracte’ theorie, welke feiten zetten mensen aan het denken over een ‘concreet’ alternatief, hoe zagen die exemplar modellen eruit. Maar ook: waarom ontdekte men gaandeweg dat men toch niet helemaal zonder die abstractie kan.
Klanken gedragen zich bijvoorbeeld wel degelijk soms hetzelfde, onafhankelijk van de context waarin ze voorkomen, Wie mensen in een experiment leert een t net wat anders uit te spreken door allerlei voorbeelden te geven van zo’n andere t (bijvoorbeeld een geaspireerde, th), die vindt dat ze na een tijdje alle t’s aspireren, niet alleen in de voorbeelden die ze gehoord hebben. Sterker nog, ze aspireren vaak ook bijvoorbeeld de k‘s, zelfs al wordt ze dat niet geleerd.
Het antwoord heet: hybride modellen, waarin bijvoorbeeld al die instanties van kat toch ook gelabeld zijn voor een k, een a en een t.. Zo zou je beide soorten effecten eruit kunnen krijgen.
Wetenschappers houden meestal niet zo van hybride modellen. Ze zitten vaak heel ingewikkeld in elkaar, zodat ze nauwelijks te begrijpen zijn. Bovendien als een model zo’n beetje alles kan verklaren, dan kan het ook eigenlijk niets verklaren. Je zegt dan: het ene kan gebeuren, maar het tegenovergestelde ook, en je doet daarmee geen enkele voorspelling over wat er daadwerkelijk gebeurt.
Het artikel eindigt daarom met een oproep aan de fonetici: er zijn nu een paar decennia lang heel veel interessante experimenten gedaan, en die hebben heel veel gegevens opgeleverd, maar de theorie kan het inmiddels eigenlijk niet meer allemaal plaatsen. Laten we naar de tekentafel gaan en hier nog eens goed over nadenken. Dat is een opmerkelijke oproep – een die je niet vaak hoort van wetenschappers, en zeker niet van fonetici, die van alle taalkundigen gemiddeld waarschijnlijk het meest gericht zijn op het verzamelen van data in mooi vormgegeven experimenten. Het geeft hoop, op mooie theorieën en warme inzichten. Laat de rest van de 21e eeuw maar komen!
Nou ja, als je constateert dat een taalgebruiker een exemplar op alle niveaus kan variëren ben je toch klaar?
Of zie ik dat te simpel?
Nee, exemplars kunnen wel gekozen worden, maar niet gevarieerd. En belangrijker nog: exemplars hebben geen ‘niveaus’, want die niveaus veronderstellen abstractie.
Hm, ‘mensen slaan alle instanties (exemplars) op van ieder woord dat ze horen. Altijd als iemand kat zegt, onthoud je hoe dat klonk. Bij het spreken produceer je daar een gemiddelde van.’ Zo’n ‘gemiddelde’, wat is dat als het geen variatie is?
Welke exemplars zouden nieuwslezers en weermannen/-vrouwen gekozen hebben? “In de middag verpraide bijen”. “…in vraihaid mag afwachten”. En is er nog hoop voor de kaikers en lijsteraars?
Van dit soort kopij wil ik méér.
Wie maakt hier de exemplars voor dat de onderzoekers te werk gaan¿ Precies. Maar wat onderzoeken te wetenschappers dan¿ Het dunne laagje bewustzijn tussen organische gebeurtenissen, wat wij bewustzijn noemen, en het fysiologische, de klank¿ Hoe wij klanken maken wordt niet beantwoord. Kan ook niet. Dat wij op verschillende manieren klanken maken daarover gaat dit onderzoek.