Talen verschillen natuurlijk: de ene taal heeft een ui-klank en de ander niet, de ene zet het lijdend voorwerp voor het werkwoord, en de ander zet hem erachter. Het in kaart brengen van al die verschillen is al een hele puzzel, maar er doet zich natuurlijk ook een hele verzameling nieuwe vragen voor met de vorm: waarom heeft taal 1 eigenschap α en taal 2 eigenschap β?
Lange tijd werden dit soort vragen door taalkundigen een beetje afgedaan als onzinnig. In essentie werden dit soort dingen gezien als toeval. Dat het Nederlands paard zegt met een p en het Duits Pferd met pf, tja, als de geschiedenis net een beetje andersom was gegaan, dan was dit misschien wel andersom geweest.
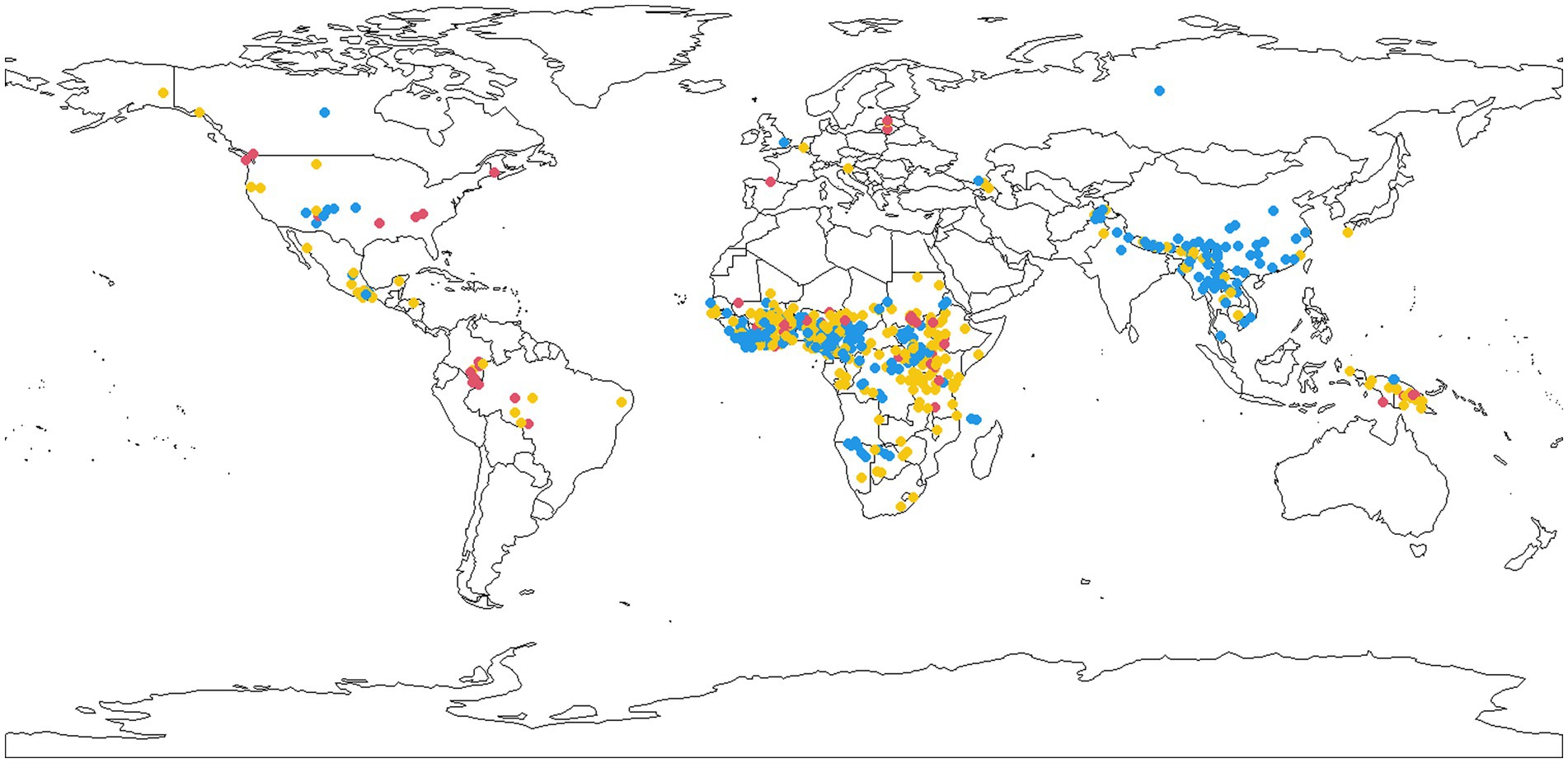
Maar de laatste jaren worden er toch pogingen gedaan om antwoorden te vinden op dit soort vragen. Door de taalkundige Søren Wichmann bijvoorbeeld, die in een nieuw artikel zich afvraagt waarom sommige talen gebruik maken van toon om verschil te maken tussen woorden en andere niet. In de meerderheid van de talen van de wereld – maar toevallig niet in de grote Europese talen – kun je verschil maken tussen twee woorden maken door ze op een verschillende toonhoogte uit te spreken, terwijl ze verder hetzelfde klinken. Op een lange hoge toon uitgesproken betekent ma in het Chinees ‘moeder’, laat je de toon eerst naar beneden gaan en dan weer omhoog, dan betekent het ‘paard’.
Wat Wichmann vooral wil laten zien: dat er een relatie is tussen hoe lang woorden gemiddeld in een taal zijn en hoeveel toonverschillen ze maken. Hoe meer lettergrepen een gemiddeld woord heeft, des te minder worden tonen ingezet. Talen met lange woorden hebben dus minder tonen dan talen met korte woorden.
Op zich is dat niet zo gek: met die tonen maak je betekenisonderscheidingen hoorbaar, maar als je woorden hebt met veel lettergrepen, zijn er toch al meer mogelijkheden om woorden van elkaar te onderscheiden. De tonen zijn dan dus als het ware niet meer nodig om al die onderscheidingen te maken.
Maar Wichmann gaat nog een stapje verder. Volgens hem worden toontalen ook gebruikt in talen met relatief veel sprekers (de grote Europese talen, zoals het Engels, zijn daar dus uitzonderingen in). De verklaring daarvoor heeft te maken met die woordlengte. Uit eerder onderzoek weten we al dat talen met veel sprekers gemiddeld betrekkelijk korte woorden hebben. Het is alsof al die sprekers samen ervoor zorgen dat de woorden slijten. Dat komt misschien doordat in ieder gesprek er een minimale druk kan zijn om zo efficiënt mogelijk te zijn en overbodigheden weg te laten. En hoe meer sprekers, des te meer gesprekken.
Maar als woorden korter worden, wordt de druk groter om verschillen tussen woorden op een andere manier uit te drukken. Bijvoorbeeld met toon.
Dat er een correlatie gevonden is tussen gemiddelde woordlengte en toon wil natuurlijk niet zeggen dat “talen met lange woorden minder toon hebben dan talen met korte woorden.” Het is hooguit zo dat hoe langer de woorden gemiddeld zijn in een taal hoe groter de kans op toon. Dat is niet hetzelfde. Basiscursus statistiek…
Nee, want het geval wil ook dat ook in de groep van talen met toon, talen met (gemiddeld) kortere woorden meer toononderscheidingen maken dan talen met (gemiddeld) kortere woorden. Ook voor die conclusie heb je overigens geen heel geavanceerde statistiek nodig.