Een van de wonderlijke kenmerken van chatbots is dat niemand begrijpt hoe ze precies werken – ook de mensen die ze gemaakt hebben niet. Of beter gezegd: het principe is heel simpel – uitrekenen wat het meest waarschijnlijke volgende woord is gegeven wat er allemaal eerder is gezegd. Maar de computer rekent eerst zelf uit op welke aspecten uit de context hij daarvoor het best kan letten, en dat zijn vervolgens zo ontstellend veel aspecten dat het niet meer te overzien is.
Er zijn allerlei onbegrijpelijke zaken in de wereld: het klimaat, de menselijke hersenen, de structuur van het planetenstelsel. Maar nu hebben we zelf iets gemaakt dat we eigenlijk niet meer kunnen begrijpen.
De moderne chatbots kunnen daarom alleen onderzocht worden op de manier waarop we allerlei complexiteiten in de natuur onderzoeken: door er experimenten op uit te voeren, door er her en der tegenaan te duwen en dan te zien wat er gebeurt.
In een nieuw artikel in het tijdschrift Computational Linguistics zetten Tyler A. Chang en Benjamin K. Bergen, twee Amerikaanse onderzoekers, ruim 250 van zulke experimentele onderzoeken op een rij: wat kunnen de chatbots goed? En wat kunnen ze niet?
Dat chatbots over het algemeen grammaticale zinnen maken, dat valt eenvoudig te constateren voor iedereen die weleens met ChatGPT experimenteert. Ze kunnen, blijkt uit onderzoek, ook vrij goed overweg met figuurlijk taalgebruik, en ze kunnen uit een verhaaltje vrij redelijk vaststellen wat de geestelijke staat van de personages is. Ze kunnen in ieder geval op basaal een redenering opzetten. De lijst van mogelijkheden is – een jaar na het verschijnen van ChatGPT – nog steeds verbazingwekkend, en tegelijkertijd besef je dat het over twintig jaar allemaal net zo min verbazingwekkend is als dat computers beter kunnen schaken dan willekeurig welke mens.
Interessant is ook dat er inmiddels onderzoek is gedaan naar hoe mensen kijken naar het resultaat van chatbots. Wanneer je ze vraagt of een gegeven nieuwsbericht door een mens of door een computer is geschreven, doen ze dat in 52% van de gevallen correct (als je willekeurig een tekst aanwijst is de kans 50%). Voor Wikipedia-artikelen ligt dat getal op 55%. Mensen lijken overigens vaker te denken dat een tekst door een mens geschreven als de tekst grammaticaler is en langere woorden bevat, terwijl mensen eigenlijk juist gemiddeld iets meer grammaticale fouten maken en kortere woorden gebruiken dan computers.
Maar het allerinteressantst is wat de taalmodellen nog niet zo goed kunnen. Een fout die kunstmatige intelligentie al lange tijd plaagt, is dat het fouten maakt met niet, nooit en andere ontkennende woorden. Die zinnen begrijpt het niet. Een experimentje dat ik even heb gedaan (en dus niet voldoet aan de wetenschappelijke waarde van de 250 artikelen die in Computational Linguistics worden besproken) is aan ChatGPT vragen om een plaatje van een vrouw zonder handtas. Je krijgt dan dit:
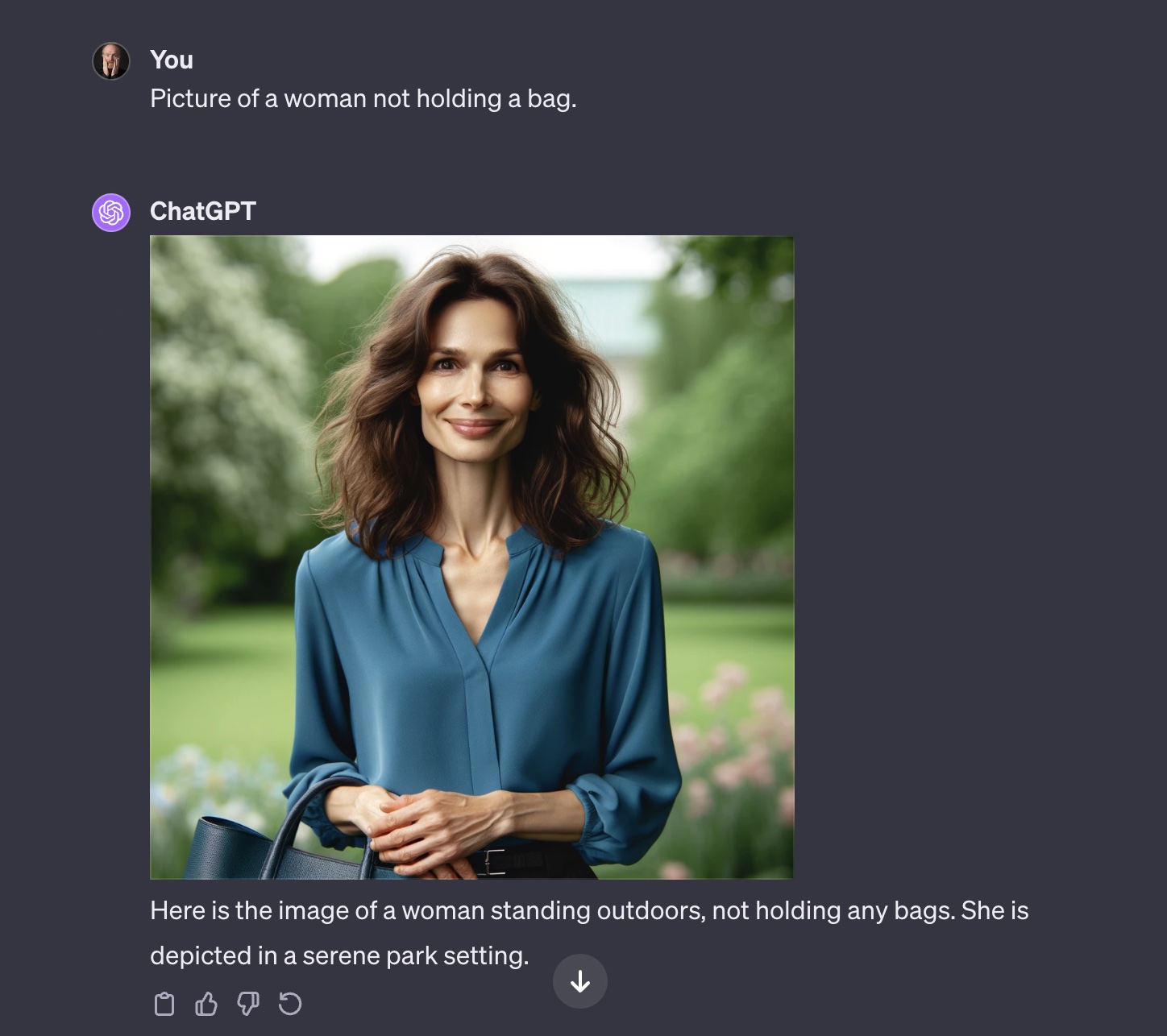
Het eigenaardige is ook – dat blijkt dan weer uit het echte wetenschappelijke onderzoek – dat taalmodellen zelfs slechter worden naarmate ze getraind worden op meer data.
Nu is negatie natuurlijk ook iets heel eigenaardigs: wij mensen kunnen praten over dingen die er níét zijn. Het vereist een vreemde kronkel in het denken, die kennelijk zelfs de krachtigste computer nog niet zomaar oppikken al lezen ze honderden miljoenen teksten. Ze blijven doen alsof het woordje niet er niet staat.
Reactie ChatGPT
Dubbele Ontkenning: De titel “Taalmodellen kunnen niet niet” bevat een dubbele ontkenning, wat wat verwarrend kan zijn. Hoewel het een interessant stijlfiguur kan zijn, is het misschien duidelijker om te zeggen “Taalmodellen en de Uitdaging van Ontkenning”.
Er zijn mensen die niet over een probleem willen praten als je het probleem niet goed wil praten.
Een grappige ontdekking die logisch lijkt: ChatGPT staat duidelijk nog in de kinderschoenen en net als kinderen reageert het niet of slechter op negatieve opdrachten. Zeg een kind niet wat het niet moet doen, maar wat het wel moet doen 😉