Wat iedereen moet weten over taal (27)
Ik veronderstel dat een komeetinslag een grootse gebeurtenis is in bepaalde wetenschappen. Een nieuwe steen uit de ruimte! Wat kunnen we daar allemaal uit leren? En als de komeetinslag een enorme impact heeft, hoe schadelijk ook, als we hem overleven: hoe interessant is dit.
De komst van chatbots zoals ChatGPT, Gemini, DeepSeek, en dergelijke is voor veel takken van de taalwetenschap te vergelijken met zo’n komeetinslag. Je kunt je zorgen maken over wat het gaat betekenen dat grote techbedrijven nu miljarden steken in een technologie die ons nog meer gaat verleiden onze diepste geheimen met ze te delen, die alles van ons stelen om het later aan ons terug te verkopen, en dat alles met een waanzinnige belasting op het milieu.
Maar het roept ook taalkundige vragen op. Tien, of zelfs vijf, jaar geleden zouden de meeste taalwetenschappers – ook ik – niet hebben voorspeld dat die apparaten nu zover zijn, dat ze aan bepaalde criteria voor taalvaardigheid nu moeiteloos voldoen, dat ze passabele zakelijke stukken kunnen schrijven en vertalen, dat je er gesprekjes mee kunt voeren waarbij je soms de illusie kunt hebben met een mens te praten.
Details
Dat laatste heeft jarenlang bekend gestaan als de Turing-test, naar de beroemde informaticus Alan Turing (1912-1954). Die test houdt in dat een menselijke scheidsrechter via een beeldscherm moet praten met een ander mens en met een computer. Als die scheidsrechter binnen een bepaalde tijd niet kan bepalen wie wie is, is de computer geslaagd. Het was voor Turing overigens niet alleen een test voor taalvaardigheid, maar voor intelligentie – zo dicht liggen die in ons denken bij elkaar.
Ik ben weliswaar al heel oud, maar ik was nog niet geboren toen Turing overleed. En de Turing-test heeft lange tijd onbereikbaar geleken. Inmiddels denk ik dat menige chatbot er bij mij voor zou slagen. De vraag is dan welke andere criteria er zijn – hoe onderscheiden computers zich dan van mensen?
De vraag is om één reden lastig te beantwoorden: de grotetaalmodellen zijn momenteel allemaal in handen van grote bedrijven. Ze zijn simpelweg te duur om te maken voor publieke instellingen, zelfs als het grote en rijke universiteiten zijn. Hoe ze precies werken valt daarmee onder het bedrijfsgeheim. Over de grote lijnen weten we wel van alles (daarover hebben de makers ook wel wetenschappelijke artikelen geschreven), maar de precieze details worden niet bekend gemaakt. Daarbij geldt ook nog dat de systemen zo ingewikkeld zijn dat ook in die bedrijven zelf waarschijnlijk niemand alles helemaal begrijpt.
Dichter bij de mens
Een belangrijk verschil is momenteel in ieder geval hoe grotetaalmodellen taal leren, namelijk door overstelpende hoeveelheden tekst tot zich te nemen, verzamelingen waaraan een mens duizenden jaren zou moeten besteden om het allemaal door te nemen. De computers gebruiken die voorbeeldteksten om er patronen in te ontdekken: na op een… staat vaker bankje dan moordzucht, als er eerder in een tekst prominent sprake is van een man, is het persoonlijk voornaamwoord hij waarschijnlijker dan zij.
Het is niet duidelijk of mensen ook op die manier taal leren, zij het dan met minder leesvoer. Met name onderzoekers uit het gebied van de kunstmatige intelligentie denken soms van wel. Een voorbeeld is de Nobelprijswinnaar George Hinton die jarenlang bij Google heeft gewerkt aan grotetaalmodellen en denkt dat zij de beste theorie geven over hoe taal werkt. Een verschil is dan in ieder geval dat wij mensen dus efficiënter zijn – maar daar kunnen we volgens sommige optimisten met chatbots ook ooit komen. Maar er is onder taalkundigen, en trouwens ook onder andere groepen AI-onderzoekers, ook scepsis of dat zo is. De recente upgrade van ChatGPT4 naar ChatGPT5 viel nogal tegen, en veel mensen zeggen dat dit komt doordat we nu de grens hebben bereikt van wat een grotetaalmodel precies kan; dat er nieuwe ideeën nodig zijn over wat er nodig is om dichter bij de mens te komen.
Ingebakken
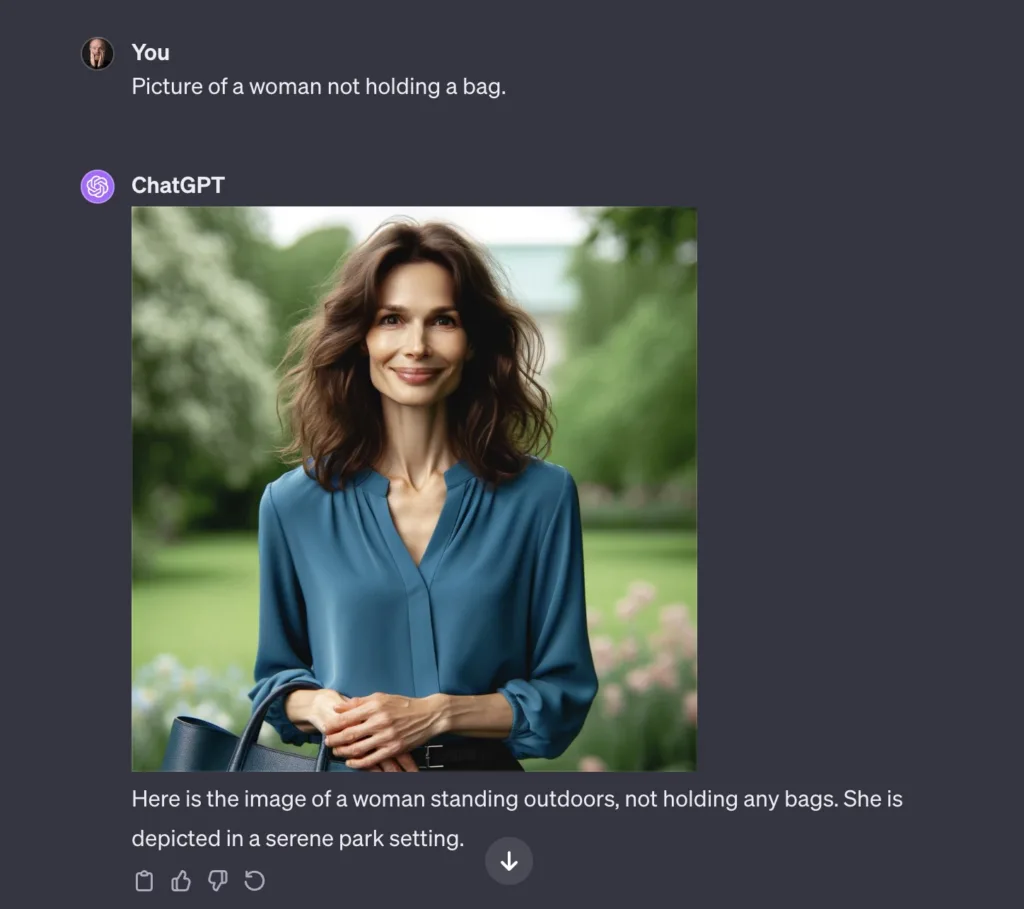
Het is niet helemaal duidelijk wat dat volgende zou moeten zijn. De ontwikkelingen gingen de laaste jaren ook best hard. Een bekend probleem was in 2023/24 bijvoorbeeld nog dat chatbots problemen hadden met ontkenningen. Vroeg je ze een plaatje van een vrouw zonder handtas te tekenen, dan kreeg je onveranderlijk een plaatje van een vrouw met een handtas. (Ik schreef er indertijd dit over.) Als ik het nu informeel test op wat chatbots waar ik toegang toe heb, lijkt dat probleem grotendeels verholpen. Zoiets geldt ook voor allerlei ingewikkelde grammaticale constructies, die de systemen vrij goed lijken te herkennen.
Voor zover ik kan zien, is het grootste probleem volgens de kritische deskundigen op dit moment dat chatbots geen model van de wereld hebben. Als ik jou ga uitleggen hoe mijn kamer er van binnen uitziet, stel ik me die kamer voor, ik loop er in gedachten rond, enzovoort. Als ik me een mens voorstel, weet ik dat die mens meestal twee armen heeft, met een hand aan iedere arm, en aan iedere hand vijf vingers. Chatbots, weten alleen dat er in de context van het woord hand regelmatig vingers voorkomen.
Nog belangrijker is dat veel taalkundig onderzoek van de afgelopen decennia heeft vastgesteld dat we in een gesprek ook een model hebben van wat de ander weet. Als ik mijn kamer aan het beschrijven ben, en ik heb uitgelegd dat de tafel tegen de wand staat, ga ik ervan uit dat dit iets is dat je vanaf dit moment weet, en dat je er ook vanuit gaat dat die tafel op zijn poten staat en niet op zijn kop – omdat ik weet dat dit de normale stand van zaken én weet dat jij dit ook weet. Als ik praat over een mens, ga ik er geen aandacht aan besteden dat die mens tien vingers heeft, omdat ik ook hier er weer vanuit ga dat wij het idee delen dat dit normaal is. Anderzijds ga ik er niet zonder meer vanuit dat jij denkt dat die persoon stugge rode haartjes op zijn vingers heeft, tenzij ik jou ken en inmiddels weet dat jij dit denkt.
We noemen dit common ground: mensen praten vanuit een gezamelijke kennisbasis. Er zijn redenen om te denken dat chatbots niet zo denken, dat ze helemaal geen idee hebben over wat hun publiek wel of niet weet, laat staan dat ze zich afvragen of hun publiek weet dat zij iets weten. Chatbots zijn daardoor vooralsnog slechter in het zich aanpassen aan hun publiek, en ook trouwens in het voeren van echt spontane conversaties, waarin mensen elkaar onderbreken, elkaars zinnen afmaken, grapjes maken waarin ze elkaars eigenaardigheden op de hak nemen, enzovoort. Dat is misschien iets dat je niet leert van het lezen van miljarden teksten, maar dat in je natuur moet zijn ingebakken.
Relevante artikelen in de Taalcanon: Hoe verstaat de computer wat ik zeg? van Arjan van Hessen en Erica Renckens, en Kan een computer zinnen ontleden? van Rens Bod
Laat een reactie achter