Iedereen kan ontleden. Als iemand praat, stort hij een continue stroom geluid over de luisteraars uit, die deze stroom op de een of andere manier uit elkaar moeten halen: wat zijn de woorden? En hoe verhouden die woorden zich tot elkaar? Een van de wonderlijke eigenschappen van de mens is dat ze dat inderdaad kan, en wel moeiteloos. Je hebt, als iemand in je moedertaal spreekt, niet eens in de gaten dat je iets aan het doen bent – bepalen welke klanken precies bij elkaar horen en een woord maken, waar de grenzen van die woorden zijn, en op welke manier die woorden gegroepeerd zijn tot woordgroepen en zinsdelen. Over het algemeen begrijp je, in ieder geval in een gewoon gesprek, precies wat er wordt gezegd, en voor je gevoel begrijp je dat meteen, terwijl de ander nog aan het praten is.
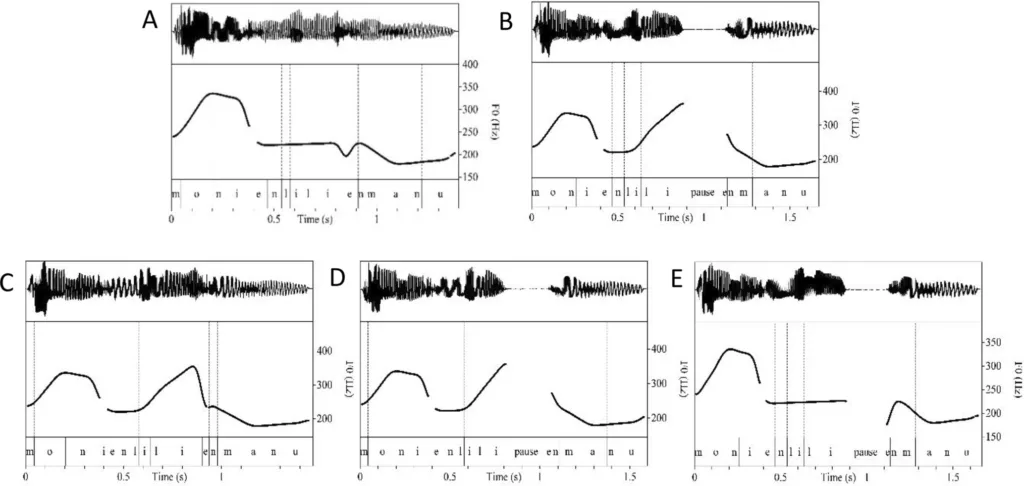
In een nieuw artikel in het tijdschrift Psychonomic Review & Bulletin draagt een groep Utrechtse taalkundigen, onder aanvoering van de promovendus Jorik Geutjes, wat bouwstenen aan voor beter begrip. Ze onderzochten hoe Nederlandstaligen de grenzen van middelgrote zinsdelen aangeven. Stel dat je het hebt over ‘Moni en Lilli en Manu’, bedoel je dan aan de ene kant Moni en Lilli, en aan de andere kant Manu? Of: aan de ene kant Moni, en aan de andere kant Lilli en Manu? Of alle drie deze personen zonder duidelijk onderscheid?
Effect
Mensen kunnen die verschillen goed maken in gesproken taal – zo, dat hun luisteraars goed begrijpen wat ze bedoelen. We weten ook al dat er in talen van de wereld in ieder geval drie verschillende aanwijzingen worden gebruikt om aan te geven dat er het einde is van een woordgroep. Stel dat je wilt zeggen ‘(Moni & Lilli) & Manu’. Dan kun je de toon omhoog laten gaan aan het einde van Lilli, of je kunt op dat woord je tempo een beetje vertragen, of je kunt na Lilli een minutieuze pauze laten vallen.
In experimenten waarin Nederlanders werd gevraagd dit soort woordgroepen te produceren, gebruikten ze alle drie die manieren: Lilli werd een beetje hoger, en een beetje trager én het werd gevolgd door een pauze. Maar vervolgens legden de onderzoekers luisteraars ook met de computer gemanipuleerde versies van de opnamen voor – versies waarin de toonhoogteverandering, of de vertraging, of de pauze, of een combinatie ervan, waren weggegumd.
En in zulke omstandigheden bleek de pauze verreweg het belangrijkst. Luisteraars herkenden een groepering niet als die pauze weg was – terwijl ze dat na het uitvlakken van de andere zaken nog steeds begrepen.
Het klinkt misschien logisch dat een pauze dat effect heeft, maar uit eerder onderzoek naar sprekers van het Duits en het Engels, toch verwante talen, bleken die andere aanwijzingen belangrijker bij het herkennen. Waarom dat zo is, is niet helemaal duidelijk. De onderzoekers zeggen dat het misschien ermee te maken heeft dat van die andere talen ook meer gebruik maken van verlenging en hogere tonen om aan te geven wat ze bedoelen – maar dan is de vraag natuurlijk waarom sprekers van het Nederlands dat minder doen.
Laat een reactie achter