Door Roland de Bonth (Instituut voor de Nederlandse Taal)
Eind januari meldde ik op Neerlandistiek dat er een nieuwe versie van het corpus Brieven als Buit (BAB) online was gekomen, deze maand kan ik meedelen dat vrijdag 26 februari ook het corpus Brieven als Buit-2 digitaal beschikbaar is gekomen voor onderzoekers en belangstellenden.
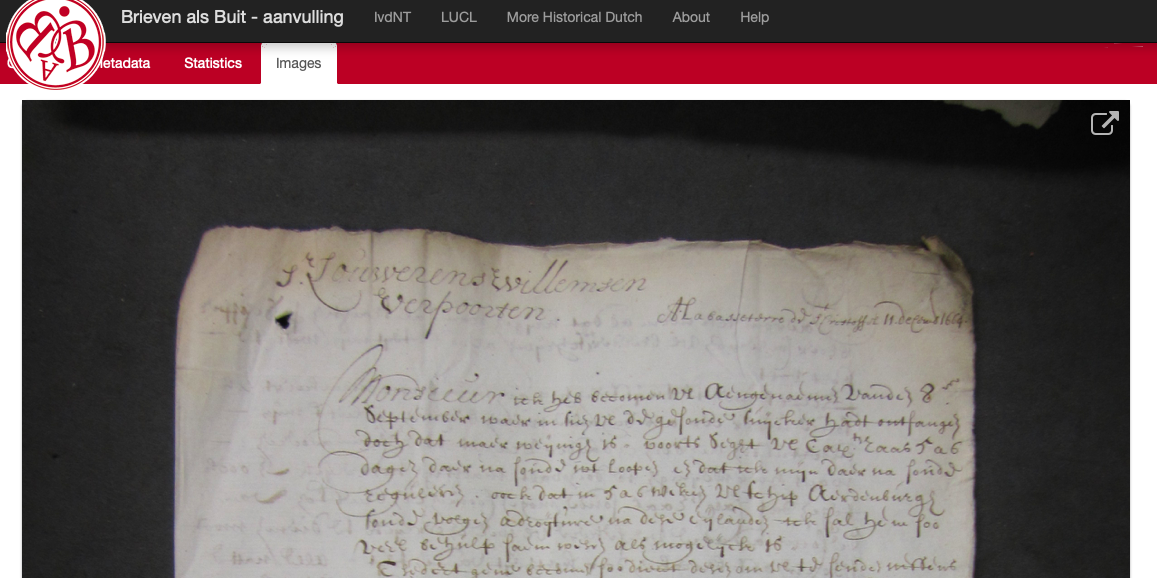
Brieven als Buit-2 (BAB2) is een spin-off van het Brieven als Buit-onderzoeksprogramma (2008-2013) aan de Universiteit Leiden, dat onder leiding stond van prof. dr. Marijke van der Wal. Na de afronding van dat onderzoek nam zij het initiatief tot BAB2. Dit resulteerde in een nieuw corpus van maar liefst 1386 Nederlandse brieven die als buit zijn meegenomen door kapers en geconfisqueerd door de Hoge Admiraliteit tijdens de oorlogen tussen Nederland en Engeland van de tweede helft van de 17e tot de vroege 19e eeuw.
BAB en BAB2
De corpusapplicatie van BAB2 ziet er hetzelfde uit als BAB – en als alle andere historische corpora die het Instituut voor de Nederlandse Taal (INT) tot nu toe online heeft gezet, zoals het Corpus Gysseling en het Corpus Middelnederlands. Een van de redenen waarom de aanvullende brieven niet zijn toegevoegd aan BAB maar een eigen corpusapplicatie hebben gekregen, is dat er enkele verschillen bestaan in de manier waarop de brieven doorzoekbaar zijn.
Zo is het oorspronkelijke BAB-corpus een gebalanceerd corpus, samengesteld voor en gebaseerd op het eerdergenoemde Brieven als Buit-onderzoek. Metadata uit de database van dat onderzoeksprogramma zijn toegevoegd aan de 1033 brieven en het INT heeft alle woorden daaruit gelemmatiseerd en grammaticaal getagd.
BAB2 daarentegen is geen uitgebalanceerd corpus, maar een aanvullende selectie uit de circa 40.000 gekaapte brieven die bewaard worden in de National Archives (Kew, Verenigd Koninkrijk). Deze verzameling brieven is nog niet geannoteerd met woordsoort of lemma, waardoor er minder zoekmogelijkheden zijn dan bij het originele Brieven als Buit-corpus.
Lexiconservice
Om het corpus BAB2 toegankelijker te maken worden er wel suggesties gegeven voor het uitbreiden van een zoekopdracht. Daarbij wordt gebruikgemaakt van de INT- lexiconservice met het historische computationele lexicon GiGaNT–HILEX. Deze service laat het zich duidelijkst uitleggen aan de hand van een voorbeeld.
Als je in de zoekbalk van de corpusapplicatie bij Word lief intikt, gaat er aan het eind van de zoekbalk een wiel draaien. Na korte tijd verschijnt een overzicht met historische spellingvarianten. Ook staat daarbij vermeld tot welke woordsoorten die verschillende woordvormen behoren. Selecteer je bijvoorbeeld alleen lief als adjectief dan blijven er veertien woorden over waaruit een keuze gemaakt kan worden. Met de knop Select all worden alle vormen in één keer aangevinkt.
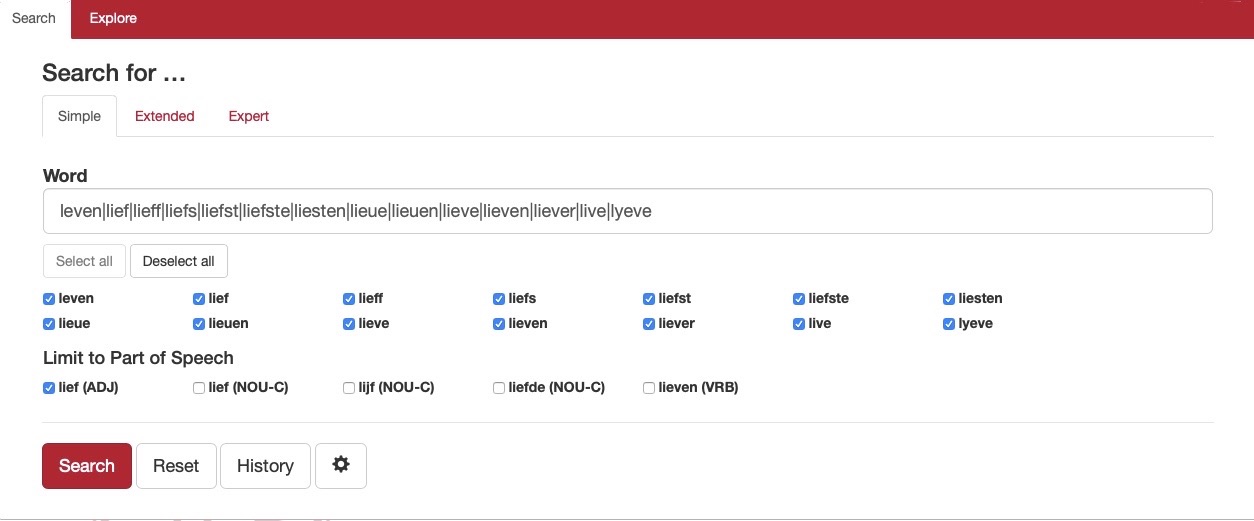
Dat boven de zoekbalk het woord Word staat, wekt de indruk dat je alleen op losse woorden kunt zoeken, maar dat is niet het geval. Met deze corpusapplicatie is het ook mogelijk een woordgroep (bijvoorbeeld lieve man) als zoekopdracht te geven. Houd er dan wel rekening mee dat die woorden in exact deze spelling in het corpus moeten voorkomen. (De lexiconservice biedt hier geen soelaas want die werkt alleen bij losse woorden.)
Wildcards
Om het aantal treffers bij zoekopdrachten naar woordgroepen aanzienlijk te vergroten brengen de wildcards ? (één willekeurig teken) en * (één of meer willekeurige tekens) uitkomst. De zoekopdracht lie?e man resulteert in lieve man, liefe man en lieue man, terwijl lie*e man maar liefst 11 treffers geeft: lieve man, liefe man, liefhebbende man, lieue man, liefve man, liefste man, Liefhebbenste Man, Lievhebbende Man, lieeve man, liefhebbende man en liefste man. Voor nog meer zoekmogelijkheden verwijs ik graag naar de uitgebreide – Engelstalige – help-functie bij BAB2.
Overzicht van de belangrijkste verschillen tussen BAB en BAB2
| BAB (originele versie) | BAB2 (aanvullingen) |
| Gebalanceerd corpus | Verzameling brieven |
| Aantal brieven: 1033 | Aantal brieven: 1386 |
| Periodes: 1661-1673; 1777-1783 | Periodes: 1661-1673; 1751-1758; 1773-1783 |
| Biedt transcripties, foto’s van de originele brieven en metadata | Biedt transcripties, foto’s van de originele brieven en metadata |
| Grammaticaal getagde en gelemmatiseerde transcripties. Dit maakt zoeken op woord én op lemma mogelijk. | Geen grammaticaal getagde en gelemmatiseerde transcripties. Dit maakt alleen zoeken op woord mogelijk. |
| Private letters (90%), business letters (10%) | Private letters (74%), private-business or business letters (26%) |
| Gender volledig onderzocht | Gender volledig onderzocht |
| Sociale klasse en leeftijd volledig onderzocht | Sociale klasse en leeftijd gedeeltelijk onderzocht |
| Autograafstatus volledig onderzocht | Autograafstatus 83% onderzocht |
Laat een reactie achter