
Kranten vormen een bijzonder interessante bron voor taalkundig, letterkundig en historisch onderzoek. Al vanaf de zeventiende eeuw worden er in de Lage Landen kranten gedrukt waarin de lezers kennis konden nemen van belangrijke nationale en internationale politieke en militaire gebeurtenissen, zoals staatsbezoeken, veldslagen en vredesonderhandelingen. Daarnaast vormden kranten een ideaal medium om pas verschenen of te verschijnen boeken aan te kondigen, maar ook om verloren ringen, weggelopen honden en gevluchte dieven onder de aandacht van de lezers te brengen.
De Koninklijke Bibliotheek in Den Haag heeft de afgelopen jaren ruim twee miljoen kranten van 1618 tot en met 1995 gescand en de foto’s via de website Delpher.nl gratis beschikbaar gesteld. Daaronder bevinden zich niet alleen dagbladen die in Nederland zijn gedrukt, maar ook Nederlandstalige kranten uit Nederlands-Indië, de Antillen, de Verenigde Staten en Suriname.
De scans van de kranten uit Delpher zijn met behulp van Optical Character Recognition omgezet in voor de computer leesbare tekst. Zo is het mogelijk geworden om daarin te zoeken naar specifieke woorden, combinaties van woorden en (historische) spellingvarianten.
Couranten Corpus
Een verhaal apart vormen de zeventiende-eeuwse kranten. De kwaliteit van de automatisch herkende tekst bleek door de kwaliteit van het toenmalige drukwerk (en daarmee van de afbeeldingen), het gebruikte (gotische) lettertype en de afwijkende taal van onvoldoende kwaliteit om er onderzoek mee te doen. Daarom hebben ruim 200 vrijwilligers onder leiding van Nicoline van der Sijs duizenden exemplaren van dertien verschillende zeventiende-eeuwse kranten die op Delpher te vinden zijn, zorgvuldig getranscribeerd via een op het Meertens Instituut ontwikkelde crowdsource-omgeving. In 2020 ontving deze dataset de Nederlandse dataprijs.
De metadata van deze handmatig overgetikte artikelen zijn door stagiairs en medewerkers van het Instituut voor de Nederlandse Taal (INT) gecorrigeerd, waarbij alle artikelen eigen metadata hebben gekregen en dubbele kranten uit de dataset zijn verwijderd. Ook zijn nieuwe metadata toegevoegd, bijvoorbeeld over genre en nieuwssoort (advertenties, binnenlands nieuws, buitenlands nieuws, etc.). De bijna 19 miljoen woorden zijn automatisch taalkundig verrijkt met modern lemma en woordsoort, zodat ze beter vindbaar zijn. Het historisch lexicon van het INT – waarin historische spellingvarianten zijn opgenomen – maakt het mogelijk dat het aantal zoekresultaten zonder al te veel moeite sterk toeneemt.
De tot nu toe getranscribeerde 17e-eeuwse kranten bevatten 109.532 artikelen en zij zijn alle opgenomen in het zogeheten Couranten Corpus, waar Nicoline van der Sijs op Neerlandistiek eerder al attendeerde. De informatie in deze kranten is interessant voor onderzoekers van verschillende disciplines, variërend van historici en historisch taalkundigen tot literatuurwetenschappers en kunsthistorici. Overigens wordt op dit moment – wederom onder leiding van Nicoline van der Sijs – met behulp van Transkribus gewerkt aan de ontsluiting van nog meer 17e-eeuwse kranten. Deze vrijwilligers hebben daarvoor inmiddels al meer dan 4000 extra pagina’s van de Amsterdamse Courant nagekeken! (Toen iets meer dan een half jaar geleden 2600 pagina’s waren nagekeken, verscheen een online gelegenheidswoordenboekje met bijzondere woorden uit 17e-eeuwse kranten.)
Onderwijs en onderzoek
De kranten uit Delpher, waaronder die exemplaren die zijn opgenomen in het Couranten Corpus, bevatten een schat aan gegevens voor (wetenschappelijk) onderzoek maar zij kunnen ook heel goed worden ingezet bij onderwijs aan leerlingen en studenten. Belangrijk is daarbij wel dat je goed moet weten wat je precies wilt onderzoeken (wat is je hoofdvraag?), hoe je dat kunt onderzoeken (wat zijn je zoektermen?) en hoe je moet zoeken (wat zijn je zoekopdrachten?). Ik zal dit hieronder uitwerken aan de hand van een concreet voorbeeld.
De wolf in Nederland
Enkele jaren geleden keerde de wolf terug op Nederlandse bodem. Filmpjes van gespotte exemplaren, berichten over doodgebeten schapen en discussies tussen voor- en tegenstanders van de aanwezigheid van dit roofdier verschenen geregeld in de krant, op de radio en op de televisie.
De laatste twee media bestonden in de zeventiende eeuw natuurlijk nog niet, maar kranten waren er al wel. Nicoline van der Sijs stelde zich de vraag hoeveel wolven er toentertijd voorkwamen, in hoeverre ze voor overlast zorgden en hoe mensen omgingen met dit dier. Zij dook daarvoor in oude kranten. De resultaten van dit onderzoekje verwerkte zij in ‘Herkomst en gebruik van het woord wolf in het Nederlands’ op historici.nl.
Met het Couranten Corpus is het veel gemakkelijker een dergelijk onderzoek uit te voeren dan met de kranten op Delpher. Het voordeel van het zoeken in het Couranten Corpus is namelijk dat je tegelijkertijd kunt zoeken naar het woord wolf zelf, maar ook naar spellingvarianten (wolff, wulf), meervoudsvormen (wolven, wulven) en naamvalsvormen (wolfs, wolve). Typ daartoe het woord wolf in de zoekbalk in, wacht tot het wieltje aan de rechterzijde is uitgedraaid en selecteer de gewenste vormen. Hieronder het resultaat voor wolf (NOU-C), dat wil zeggen noun common ‘zelfstandig naamwoord’:
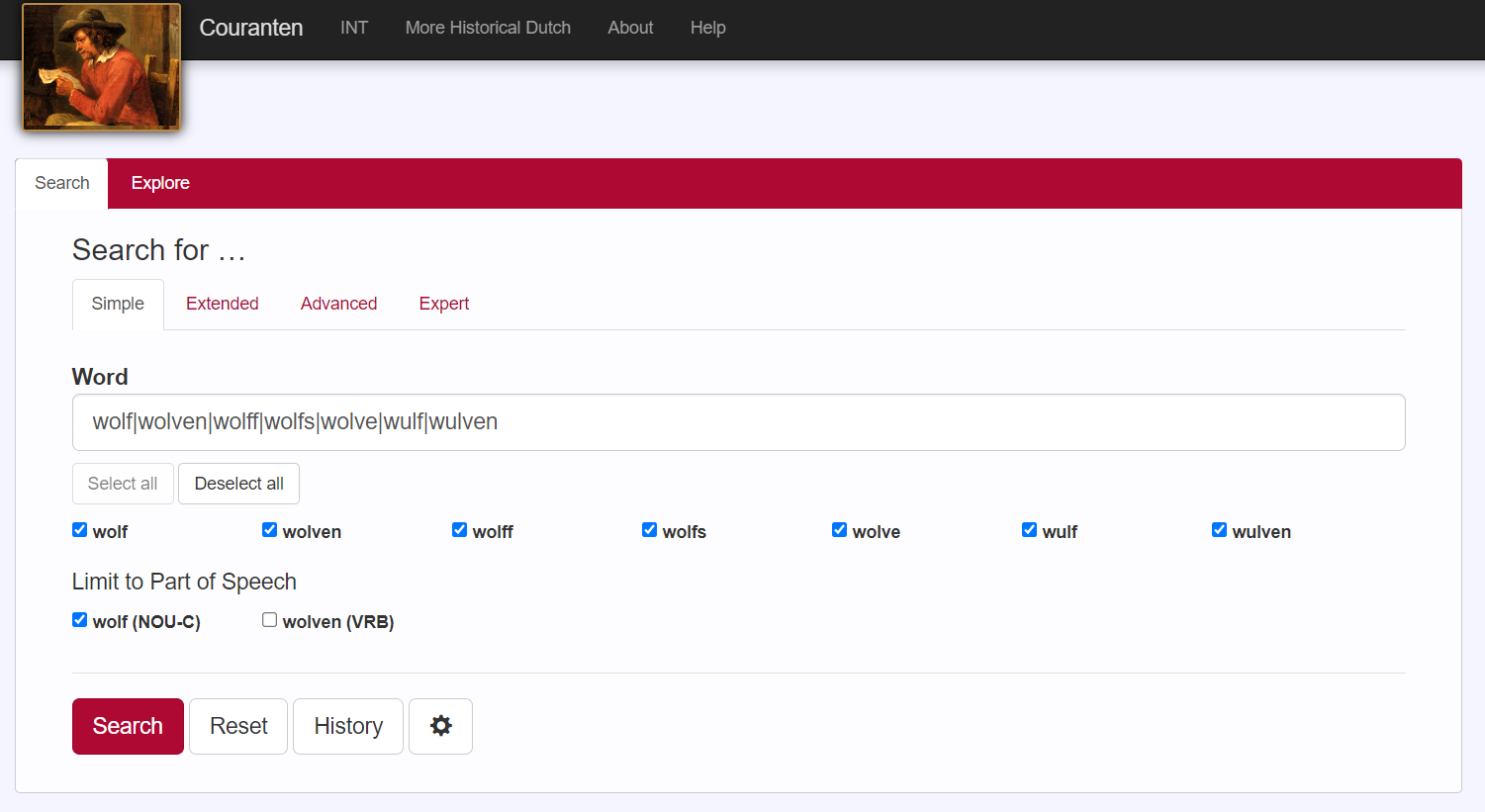
Deze zoekopdracht levert 260 treffers op, maar kan met deze zoekopdracht al teruggebracht worden tot 145 treffers. Omdat de woorden automatisch taalkundig verrijkt zijn maar niet handmatig gecorrigeerd zijn, staan daar abusievelijk ook nog eigennamen tussen: “Den Grave Wolf van Oetingen is alhier gearriveert”. Maar bij het doornemen van de resultaten springen die vanzelf in het oog, zeker als je bij de resultaten rechtsonder drukt op Hide Titles.
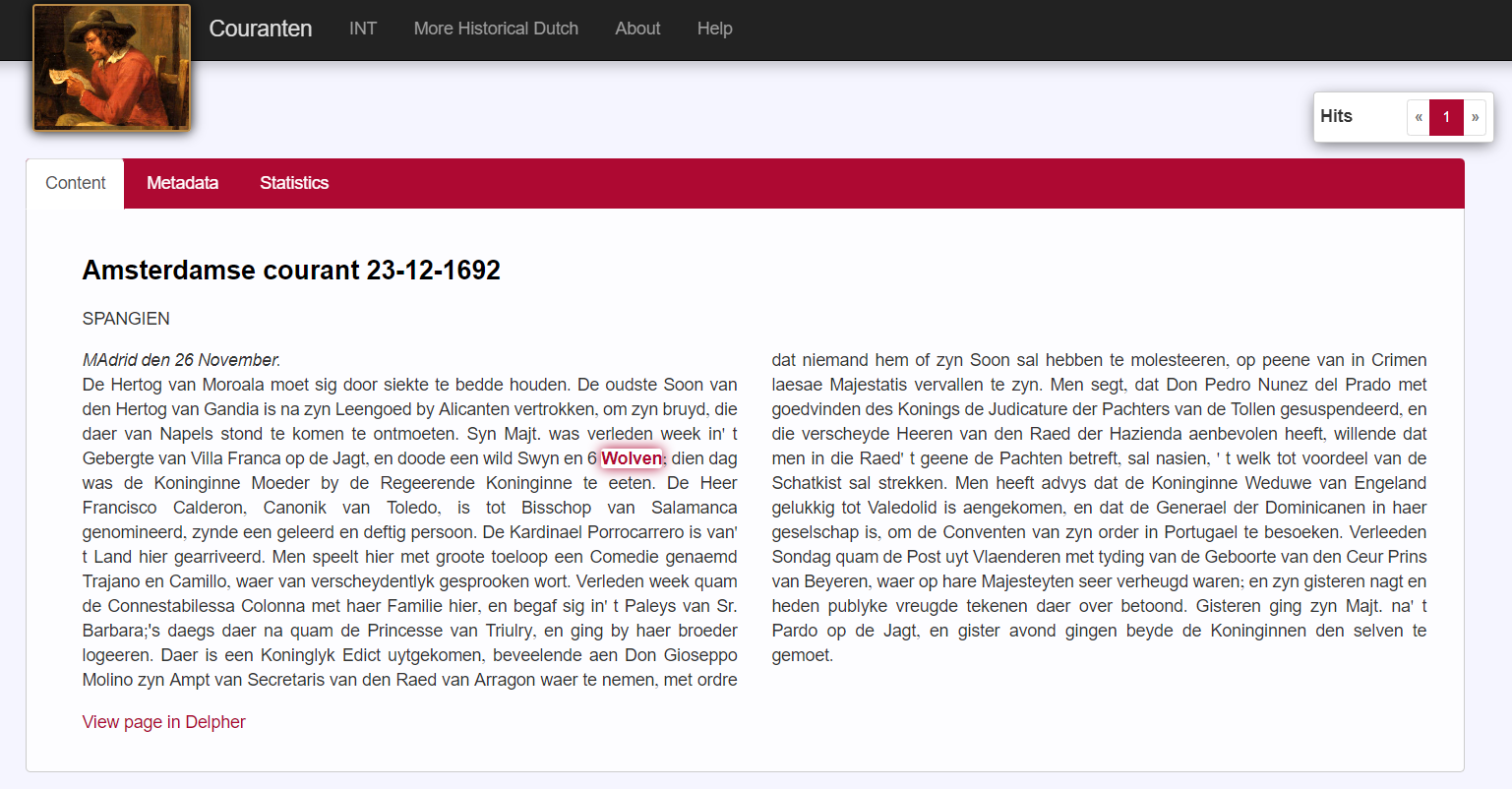
Klik je in het resultatenoverzicht op een rode krantentitel, dan ga je naar het volledige krantenartikel. Het gezochte woord is daarin met een schaduw gemarkeerd:
Wie benieuwd is hoe dit artikel er in de originele krant uitziet, kan linksonder klikken op View page in Delpher. Houd er wel rekening mee dat je niet altijd direct op de juiste krantenpagina uitkomt; soms moet je virtueel bladeren
Omdat er aan elk krantenartikel in het Couranten Corpus metadata zijn toegevoegd, kun je naar hartenlust filteren. Bijvoorbeeld op datum, op plaatsnaam, op krantentitel, op teksttype. Daarmee kun je het aantal treffers beperken en specificeren. Zo zijn er in de Amsterdamse Courant uit dit corpus in de hele zeventiende eeuws slechts vijf krantenberichten uit Nederland te vinden waarin het woord wolf voorkomt. Daarbij gaat het drie keer om de naam van een kapitein en twee keer om de naam van een schip. Van het dier ontbreekt in deze krant ieder spoor.
Het Couranten Corpus biedt verschillende mogelijkheden om resultaten te groeperen, bijvoorbeeld op Word. Dat levert het volgende overzicht op:
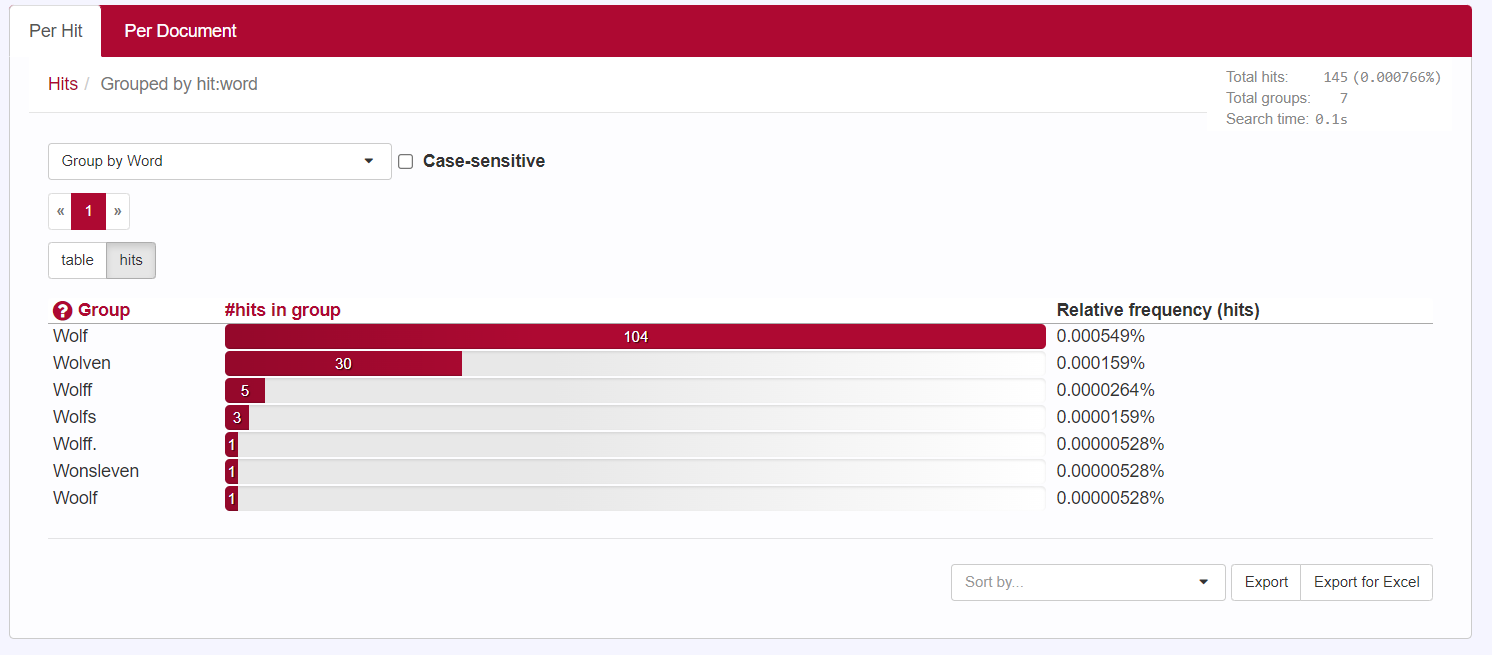
Ook is het mogelijk de resultaten op een aantal manieren te sorteren. Wanneer je voor een alfabetische woordvolgorde kiest, komen alle wolven keurig onder elkaar te staan. En omdat wolven vaak leven in roedels, is de kans groot dat we hiermee vooral de roofdieren vinden. Zo staat alle informatie die we nodig hebben voor het schrijven van een stukje over de wolf in de zeventiende eeuw overzichtelijk bij elkaar, zoals de context voor en na de treffer duidelijk laat zien:
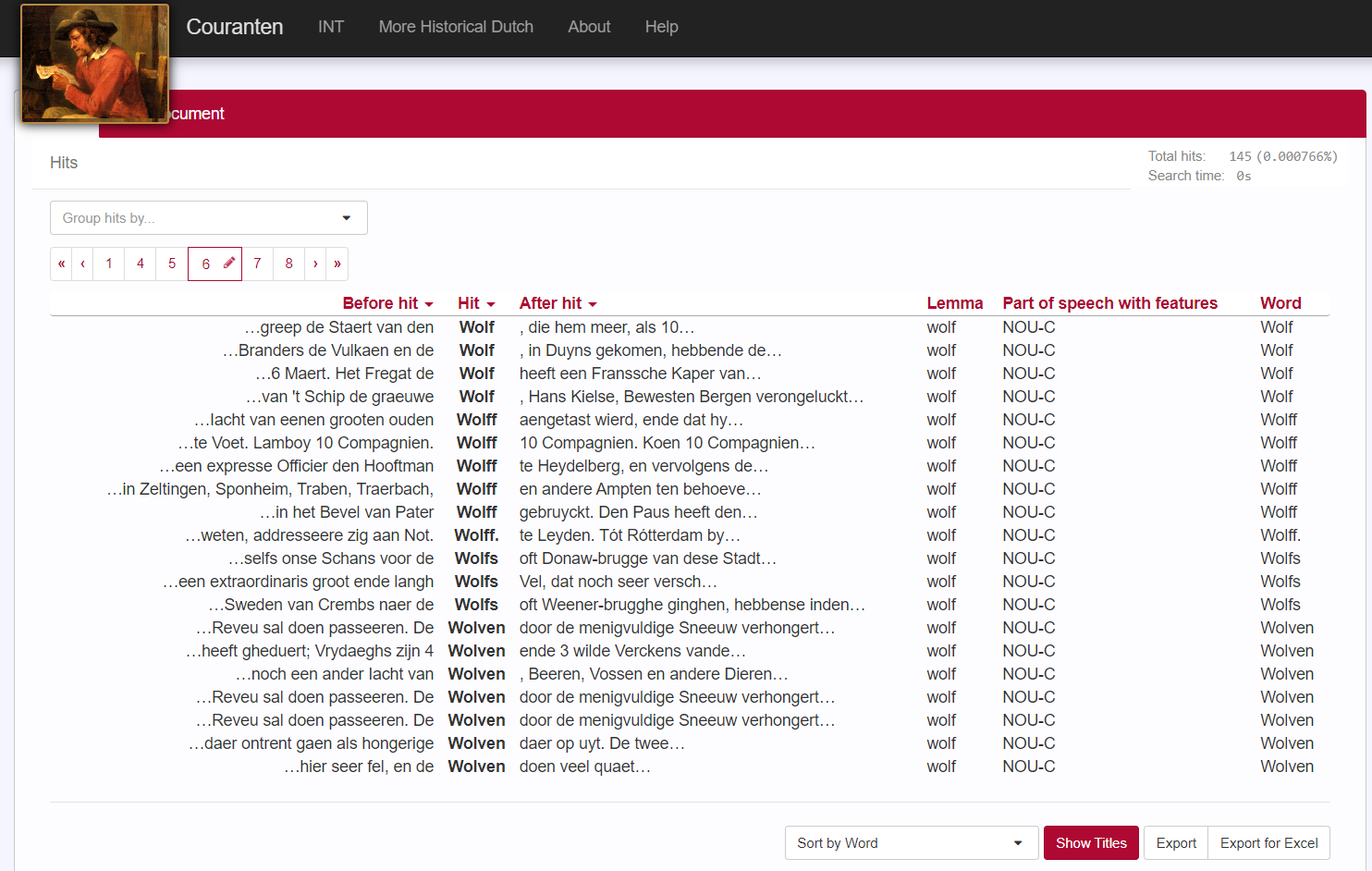
Op deze plek is het niet mogelijk uitgebreider in te gaan op alle zoek- en sorteermogelijkheden die het Couranten Corpus biedt. Wie meer wil weten, verwijs ik graag naar de zeer uitgebreide Engelstalige handleiding, met tal van voorbeelden, hyperlinks naar zoekopdrachten en schermafbeeldingen. Met de daaruit opgedane kennis wordt ook het zoeken in de andere historische corpora van het Instituut voor de Nederlandse Taal (INT) een peulenschilletje, want die maken gebruik van dezelfde corpusapplicatie.
Hierboven heb ik aan de hand van het woord wolf laten zien hoe je het Couranten Corpus kunt inzetten voor het schrijven van een gedocumenteerde tekst. Op eenzelfde wijze kunnen voor een opdracht bij het vak Nederlands – uiteenzetting, (profiel)werkstuk – ook talloze andere woorden of onderwerpen onderzocht worden. Juist vanwege die rijkdom zal er voor elke leerling wel iets van haar of zijn gading bijzitten. Kortom, het Couranten Corpus is een bron die zich heel goed leent voor onderzoek in de klas.
Voor vragen en opmerkingen over het Couranten Corpus kunt u te allen tijde contact met me opnemen (roland.debonth@ivdnt.org).
*Dit is een licht gewijzigde en uitgebreidere versie van het stuk dat ik eerder met Cefas van Rossem schreef voor de Conferentiebundel van HSN 36 in Rotterdam.
Laat een reactie achter