
De oudste kranten in de Republiek en de Spaanse Nederlanden verschillen essentieel van elkaar in opzet, nieuwssoorten en vrijheid van meningsuiting, zo bleek in deel 1. In hoeverre had dat invloed op het taalgebruik? En bestonden er (dialect)verschillen tussen de noordelijke en zuidelijke kranten? Hieronder probeer ik deze vragen met behulp van de computer te beantwoorden.
Een eerste doorkijkje
Er bestaan allerlei nuttige tools die de opbouw van een corpus zichtbaar maken. Die geven overigens allemaal net iets andere resultaten, maar de verschillen zijn miniem. Ik heb gekozen voor de gratis Voyant Tools, omdat die een aantal interessante extra opties hebben. Wel ben ik er inmiddels door schade en schande achter gekomen dat de tool (zonder waarschuwing) standaardinstellingen heeft die tot onverwachte en ongewenste resultaten leiden: zo worden automatisch allerlei zeer frequente woorden als den, de en van weggefilterd. Die standaardinstellingen heb ik uitgezet.
Ik heb Voyant gevoed met drie ongeveer even grote corpora: de complete teksten van de Nieuwe Tijdinghen (1605-1629), de nieuwsberichten van het Couranten Corpus uit 1620 en 1621, en een corpus teksten uit diverse moderne kranten uit 2023 (uit het Corpus Hedendaags Nederlands). Ik heb gekozen voor de jaren 1620 en 1621 uit het Couranten Corpus omdat die jaren ongeveer evenveel woorden en krantenartikelen bevatten als het corpus van de Nieuwe Tijdinghen, en omdat in die jaren de meeste krantenafleveringen verschenen van zowel de zuidelijke als de noordelijke kranten, zo bleek in deel 1. Figuur 1 toont een overzicht van het totale aantal woorden (tokens), het aantal verschillende woorden (types) en de verhouding daartussen voor ieder corpus (type/token-verhouding).
| Bron | Couranten Corpus 1620-1621 | Nieuwe Tijdinghen 1605-1629 | Kranten 2023 |
| Totaal aantal woorden (tokens) | 106.023 | 105.907 | 107.402 |
| Aantal verschillende woorden (types) | 11.469 | 14.544 | 19.740 |
| Type/token-verhouding | 0.108 (10,8%) | 0,137 (13,7%) | 0,184 (18,4%) |
Wat opvalt is dat het aantal types en daarmee ook de type/token-verhouding (het aantal types gedeeld door het aantal tokens) in het Couranten Corpus fors lager ligt dan in de andere corpora. De moderne kranten hebben verreweg de hoogste verhouding. Dat is contra-intuïtief: immers, in de oude kranten is de spelling nog niet geüniformeerd (een officiële spelling bestaat immers pas vanaf 1804) en moderne tools zijn niet in staat de spellingvarianten te herleiden tot één en dezelfde grondvorm. Hoe komt het dan dat de vormvariatie in de moderne krant groter is dan in de oude?
Bestudering van de data toont dat de variatie in de moderne krant geheel op het conto komt van persoons-, plaats-, merk- en bedrijfsnamen, die in de moderne kranten het uitgangspunt voor het nieuws vormen, en waarvan duizelingwekkende aantallen worden genoemd. Weliswaar worden in de oude kranten ook best veel plaatsnamen genoemd, maar het aantal personen dat een rol speelt in het nieuws is veel beperkter: centraal staan vooral hoogwaardigheidsbekleders, die ook nog vaak worden aangeduid als de Keyser, Paus of Coning. Merknamen en bedrijfsnamen spelen überhaupt geen rol.
Blijft over de vraag hoe het verschil tussen het Couranten Corpus en de Nieuwe Tijdinghen verklaard kan worden. Je zou immers verwachten dat de type/token-verhouding in die contemporaine kranten min of meer gelijk is, maar dat blijkt niet het geval. Het venijn blijkt in de staart te zitten, namelijk in de laagst frequente woorden. In de Nieuwe Tijdinghen hebben maar liefst 8.592 woorden frequentie 1, terwijl het Couranten Corpus er daarvan slechts 6.451 heeft.
Om wat voor soort woorden gaat het dan? Het blijkt deels om heel gewone woorden te gaan, zoals zeyl, schuldt en zpijt. Die woorden komen in de Nieuwe Tijdinghen ook voor in andere spellingen zoals seyl (5x), schuld (1x), schult (6x) en spijt (8x), terwijl het Couranten Corpus voor deze periode alleen de spellingen seyl, schult en spijt vermeldt. De spelling zp– was ook toen heel ongebruikelijk en komt dan ook niet voor in het Couranten Corpus, maar de Nieuwe Tijdinghen spellen ook eenmaal zpeuren en zpel. Dat betekent dus dat de Nieuwe Tijdinghen een grotere spellingvariatie kennen dan het Couranten Corpus. In dat laatste is de spelling regelmatiger: er komen uiteraard ook spellingvarianten voor, maar daarin zit meer regelmaat: zo komt elleboghen 10x voor en ellenboghen 9x (ja, ook toen vormde de tussen-n kennelijk al een spellingsprobleem!). In de Nieuwe Tijdinghen zijn de varianten vaker eenmalig, zo wordt eenmaal elnboghen genoemd en eenmaal elenboghen.
Dat de Nieuwe Tijdinghen meer spellingvariatie kenden dan het Couranten Corpus, komt wellicht doordat het Couranten Corpus veel meer een eenheid in genre was, terwijl de Nieuwe Tijdinghen diverse genres vertegenwoordigden: ze bevatten naast nieuwsberichten ook liedjes, gedichtjes, dialogen en dergelijke, die een deels andere woordenschat vergen en die wellicht – inclusief de spelling – waren overgenomen uit andere bronnen.
De frequentste woorden
Verschillen tussen de corpora zijn niet alleen te vinden onder de minst frequente woorden maar ook onder de meest frequente. Voyant geeft twee manieren waarop je daarnaar kunt kijken, namelijk met of zonder de instelling van een stoplijst. Een stoplijst bevat de woorden die in iedere tekst, ongeacht genre of stijlniveau, het vaakst voorkomen. Dergelijke woorden zijn dus op geen enkele wijze distinctief. In de praktijk gaat het vooral om korte functiewoorden als lidwoorden, voorzetsels en voornaamwoorden.
Figuur 2 geeft een overzicht van de meest frequente woorden met en zonder stoplijst volgens Voyant. Voyant geeft helaas geen informatie over wat de tool beschouwt als Nederlandse stopwoorden; het gaat in ieder geval om stopwoorden in het moderne Nederlands, want het oudere ende ‘en’ is niet als stopwoord herkend. Daarnaast zijn in Figuur 2 de woorden opgenomen die volgens Voyant kenmerkend zijn voor ieder corpus in vergelijking met de andere twee corpora. Opnieuw ontbreekt in Voyant een definitie van ‘kenmerkend’, maar uit het feit dat de kenmerkende woorden gedeeltelijk overlappen met de frequentste woorden (met stoplijst), blijkt dat frequentie in ieder geval een rol speelt in de definitie.
| Bron | Couranten Corpus | Nieuwe Tijdinghen | Kranten 2023 |
| Frequentst zonder stoplijst | ende (3886); van (2715); den (2373); de (2372); die (2055) | ende (3913); van (3389); de (3286); den (2712); te (1496) | de (6174); het (3090); van (2952); een (2753); in (2450) |
| Frequentst met stoplijst | ende (3886); sich (763); oock (706); sijn (459); volck (457) | ende (3913); soo (663); wt (497); oft (442); oock (425) | we (497); je (469); jaar (380); zegt (177); twee (174) |
| Kenmerkende woorden | ende, dito, sich, oock, sijn | ende, ouer, soo, wt, ghy | we, je, jaar, gaat, mensen |
Volgens de bekende wet van Zipf komt het meest voorkomende woord in een corpus ongeveer twee keer zo vaak voor als het op een na frequentste woord, dat weer twee keer zo vaak voorkomt als het derde frequentste, enzovoort. Voor de frequentste woorden in het Couranten Corpus en de Nieuwe Tijdinghen geldt deze wet globaal, maar niet precies; dat is ongetwijfeld het gevolg van de grotere spellingvariatie in de zeventiende eeuw: Voyant beschouwt verschillende spellingen voor hetzelfde woord immers als aparte woorden.
Het is niet verrassend dat de frequentste en kenmerkendste woorden in de oudere corpora behoorlijk wat overlap vertonen, maar er zijn toch wel wat opmerkelijke verschillen, met name in de voornaamwoorden. Zo heeft hetwederkerende voornaamwoord sich in het Couranten Corpus een heel hoge frequentie (‘hij maeckt sich gereet’), terwijl dit in de Nieuwe Tijdinghen slechts acht keer voorkomt! De Nieuwe Tijdinghen blijken het persoonlijk voornaamwoord van de derde persoon als wederkerend voornaamwoord te gebruiken, soms versterkt met zelf. Enkele voorbeelden zijn (ik heb het wederkerend voornaamwoord gecursiveerd):
- in eyghen persoone hem aldaer bevindende,
- Tot wat ellende, hebt ghy v selven begeuen,
- 40. vande selve Soldaten hebben hen begeuen in den dienst van zijne Keyserlijcke Majesteyt,
- daer mede hy hem in dienste vande Morauiers hadde begeuen, heeft hem door de Heeren staten laten beweghen, hem in den dienst van zijn Keyserlijcke Majesteyt te begeuen,
- Tijdinghe hoe dat […] den meestendeel vande Standen ende Steden hun tot ghehoorsaemheyt willen begeven aen de Keyserlijcke Majesteyt,
- zy moeten eerst haerlieden gansch begeven onder den Keyser.
Het gebruik van zich als wederkerend voornaamwoord is in deze periode een innovatie. Zich is ontleend aan het Duits of oostelijke dialecten. Zeventiende-eeuwse Hollandse grammatici pleitten ervoor een verschil te maken tussen de vorm van het wederkerend en het persoonlijk voornaamwoord. Zo wordt namelijk duidelijk of het voornaamwoord terugslaat op het onderwerp of op iemand anders; in de woorden van spraakkunstenaar Samuel Ampzing in 1628: ‘so segge ik, hy heeft sich bekeerd, dat is, sich selven; ofte hy heeft hem bekeerd, dat is, eenen anderen.’ De Amsterdamse kranten hanteren dit verschil al, de Nieuwe Tijdinghen (nog) niet.
Voyant noemt verder ghy als kenmerkend voor de Nieuwe Tijdinghen. In het Couranten Corpus komt dit voornaamwoord in de jaren 1620-1621 helemaal niet voor. De reden ligt voor de hand: in de zakelijke nieuwsberichten van het Couranten Corpus is het zelden nodig een tweede persoon te gebruiken, net zo min trouwens als een eerste persoon. Zo komt ick slechts eenmaal voor in de zin ‘Ick hebbe in mijn laetste [schrijven] vermelt’ (waarschijnlijk een foutje van de uitgever, zo bleek in het vorige stuk) en eenmaal in de directe rede: ‘als hy haer nu sach heeft hy tweemael weenende ghesproocken: Och wat heb ik ghedaen’. De Nieuwe Tijdinghen bevatten, anders dan het Couranten Corpus, naast nieuwsberichten ook tekstsoorten als gedichten en liedjes, waarin een eerste en een tweede persoon wél gepast is. Ick komt in de Nieuwe Tijdinghen dan ook maar liefst 183 keer voor. Overigens komen ghy(lieden), u en ick in de latere jaren van het Couranten Corpus wél wat vaker voor, al blijft het gebruik ervan voornamelijk beperkt tot officiële bekendmakingen en directe redes.
Dat wt en ouer als kenmerkend gelden voor de Nieuwe Tijdinghen, heeft slechts te maken met de spelling van deze woorden: het Couranten Corpus spelt voornamelijk uyt en uitsluitend over. En dat dito kenmerkend is voor het Couranten Corpus komt doordat in deze kranten herhaalde maandnamen in de koppen consequent met dito worden aangeduid: ‘Wt Praghe den 6. dito.’ De overige verschillen tussen de kranten – sijn, soo, oft en volck – zijn terug te voeren tot het toeval.
Zinslengte
Moderne journalisten leren dat lange zinnen moeilijk te begrijpen zijn voor lezers. Hoe zat dat in het verleden, lette men toen ook al op de zinslengte? Figuur 3 laat het gemiddelde aantal woorden per zin zien, zoals berekend door Voyant. Voor een evenwichtige vergelijking heb ik in het Couranten Corpus de punten na een cijfer en maandnaam in de koppen verwijderd (‘Uyt Venetien den 1. Iunij.’), want door het enorm hoge aantal koppen in deze kranten leverde dit een vertekend beeld op: de tool beschouwt namelijk alles wat tussen twee punten staat als een zin.
| Bron | Couranten Corpus | Nieuwe Tijdinghen | Kranten 2023 |
| Gemiddeld aantal woorden per zin | 39,7 | 27,3 | 16,40 |
| Aantal leestekens | 10.568 | 10.787 | 4.596 |
| Totaal aantal tekens (excl. spaties) | 586.431 | 572.024 | 555.529 |
| Gemiddeld aantal letters per woord | 5,40 | 5,24 | 5,09 |
Uit Figuur 3 blijkt dat de zinnen in het Couranten Corpus verreweg het langst zijn. In de Nieuwe Tijdinghen zijn ze fors korter, wat ongetwijfeld opnieuw komt doordat er naast de nieuwsberichten ook allerlei andere teksten zoals gedichten in deze kranten zijn opgenomen. In de moderne kranten ligt het gemiddelde nog veel lager, natuurlijk doordat journalisten tegenwoordig het advies krijgen om korte zinnen te schrijven.
Lange zinnen bevatten meestal meer bijzinnen dan korte. Klopt dat ook voor deze corpora? Daarover geeft Voyant geen informatie. Met Word kun je echter gemakkelijk tellen hoeveel komma’s, puntkomma’s en dubbelepunten er in een tekst staan. Nu blijkt dat de Nieuwe Tijdinghen zelfs wat meer leestekens bevatten dan het Couranten Corpus, hoewel de zinnen in de Nieuwe Tijdinghen korter zijn: in de Nieuwe Tijdinghen is dus vaker voor de leesbaarheid een leesteken toegevoegd. Dat in de moderne kranten slechts half zoveel leestekens voorkomen als in de oude kranten is het logische gevolg van de kortere zinnen, die per definitie minder bijzinnen bevatten. Daar moet wel aan worden toegevoegd dat we tegenwoordig enkele nieuwe leestekens kennen die vroeger nog niet gebruikt werden, zoals gedachtestreepjes en aanhalingstekens.
Tot slot heb ik – ook via Word – het totale aantal tekens van ieder corpus opgevraagd. Word telt leestekens mee, dus om het gemiddelde aantal letters per woord uit te rekenen heb ik de leestekens (inclusief punten) van het totale aantal tekens afgetrokken en het resultaat gedeeld door het totale aantal woorden (tokens). Dit levert een globale indruk op van het gemiddelde aantal letters per woord. Dat blijkt, interessant genoeg, in alle drie de corpora te liggen op ruim vijf letters. De gemiddelde woordlengte lijkt dus in de loop van de tijd constant te blijven, althans als we kijken naar alle tokens. Dat gemiddelde wordt beïnvloed door de hoogfrequente korte functiewoorden. Daarom is het interessant om te bekijken of de verdeling van de tokens over de verschillende woordlengtes eveneens constant is, of dat die verandert door de tijd heen.
Woordlengte
Om de woordlengtes in de verschillende corpora te bekijken, heb ik de woordvormen (types) met hun frequentie (tokens) uit Voyant gelicht. In de zeventiende-eeuwse kranten komen veel getallen voor (aantallen legereenheden, soldaten, paarden, maanddagen, etc.): die heb ik allemaal weggelaten, zodat alleen woorden overbleven. Aan ieder type heb ik via Excel automatisch de woordlengte toegevoegd. Vervolgens heb ik de telfunctie van het databaseprogramma Filemaker Pro de frequenties van alle woordlengtes (types en tokens) laten berekenen. (Ja, wie niet kan programmeren moet een list verzinnen…). Omdat de aantallen types en tokens in de corpora niet exact gelijk zijn (zie Figuur 1) en dat op typeniveau enige vertekening bleek te geven, heb ik alle gegevens omgerekend naar procenten. De resultaten zijn te vinden in Figuur 4 en 5.
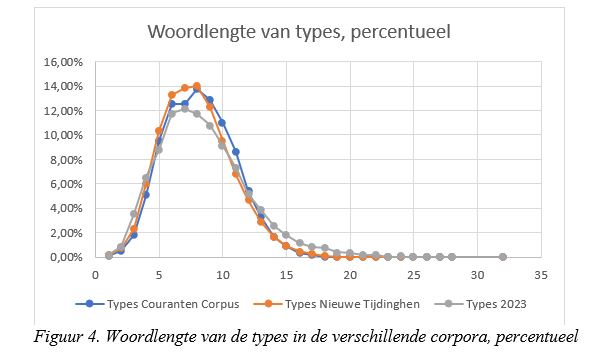
Uit Figuur 4 blijkt dat de curves van de types in de drie corpora grotendeels samenvallen, maar er zijn toch wel wat opmerkelijke verschillen. Zo ligt de top niet op dezelfde woordlengte: in de moderne kranten ligt hij bij woordlengte 7, bij de oude kranten op woordlengte 8. Bovendien steekt de top van de Nieuwe Tijdinghen (woordlengtes 6, 7 en 8) boven die van de andere bestanden uit, terwijl het Couranten Corpus bij woordlengte 7 een dipje vertoont.
De top van de moderne kranten ligt dus onder die van de oude kranten, wat betekent dat er procentueel gezien minder types zijn met lengte 6, 7 of 8. Daarentegen gaat de daling in de moderne kranten minder hard: er zijn meer woorden met een lengte van 14 letters of meer. Tot slot loopt de staart langer door: in de moderne kranten komen enkele woorden voor met 27 letters (zoals verantwoordelijkheidsgevoel), met 28 letters (Wereldgezondheidsorganisatie) en zelfs met 32 letters (arbeidsongeschiktheidsregelingen), terwijl in de oude kranten woorden met meer dan 18 letters heel zeldzaam zijn.
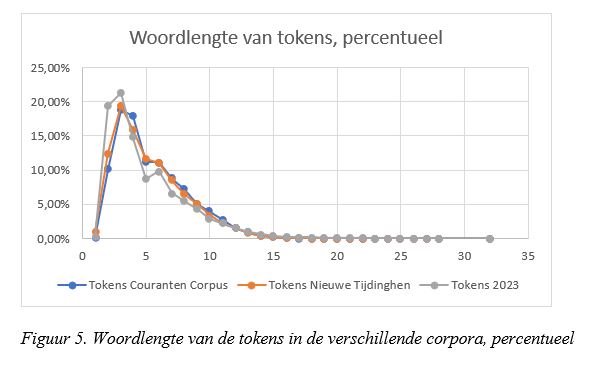
De tokens in Figuur 5 laten een andere verdeling zien dan die van de types: de absolute top wordt nu bereikt door de moderne kranten en wel met woorden met een lengte van 2 en 3 letters, samen ruim 40% van alle tokens uit die kranten. Bij de oudere kranten ligt de top bij woorden met een lengte van 3 en 4 letters. Vanaf de top zet een geleidelijke daling in, behalve bij woordlengte 6: bij die woordlengte vertonen de moderne kranten een stijging in plaats van een daling en staat de daling in het Couranten Corpus stil (het aantal tokens met woordlengte 6 is gelijk aan dat met woordlengte 5). Alleen in de Nieuwe Tijdinghen zet de daling ook bij woordlengte 6 geleidelijk door.
Uit de Figuren 4 en 5 kunnen we enkele verschillen opmaken tussen de oude en de moderne kranten. Om te beginnen blijken woorden in de loop van de tijd in het Nederlands korter te zijn geworden: de top van de grijze lijn die de lengte in de moderne kranten aangeeft, ligt telkens eerder dan die in de oude kranten, en bij de tokens ligt die top niet alleen eerder maar ook veel hoger. Dat betekent dat korte woorden tegenwoordig frequenter worden gebruikt dan vroeger. Die korte woorden zijn voornamelijk functiewoorden zoals de lidwoorden de, het, een, den, voorzetsels als in, van, voor en voornaamwoorden als hij, zij.
Een tweede, tegengestelde, conclusie is dat woorden in de loop van de tijd in het Nederlands langer zijn geworden: de moderne kranten hebben meer lange woorden en langere woorden dan de oude kranten. De reden is dat tegenwoordig drieledige samenstellingen of afleidingen heel gewoon zijn, terwijl die in de zeventiende eeuw niet of nauwelijks voorkwamen.
Dat de gemiddelde woordlengte zowel vroeger als tegenwoordig rond de 5 letters ligt, zoals bleek uit Figuur 3, is dus het gevolg van twee tegengestelde bewegingen: aan de ene kant worden woorden in de loop van de tijd verkort en aan de andere kant worden samenstellingen en afleidingen steeds langer.
Verkorten
Blijft over de vraag waardoor, wanneer en hoe woorden in de loop van de tijd korter zijn geworden. Dát woorden in de loop van de tijd vaak korter worden, is geen nieuw inzicht. Een woord als augustus spreken we al lange tijd uit als oogst, natuurlijk wordt tuurlijk, etc. Hier speelt taaleconomie een rol, en Zipf wees er al op dat woordlengte omgekeerd evenredig is aan frequentie oftewel: de frequentste woorden zijn vaak het kortst. Jesse de Does wees me op een interessant artikel van Sigurd, Eeg-Olofsson & Van de Weijer, die de theoretische distributie van woordlengte in het moderne Engels, Zweeds en Duits hebben gevangen in een wiskundige formule. Het zou interessant zijn die formule ook voor de oude en moderne kranten toe te passen maar dat gaat mijn vermogens verre te boven. Bovendien ben ik vooral geïnteresseerd in een inhoudelijke verklaring voor de verschillende woordlengtes in de oude en de moderne krantencorpora.
Dat tegenwoordig woorden vaak korter zijn dan vroeger, zal zeker deels te herleiden zijn tot de standaardspelling: daardoor is de spellingvariatie sterk ingedamd. Bovendien zijn medeklinkercombinaties die vroeger veelvuldig voorkwamen, vereenvoudigd (de oude spellingen vertreck, ghecomen, vleesch, niemandt zijn gewijzigd in vertrek, gekomen, vlees, niemand) en worden lange klinkers vaker met één dan met twee letters gespeld, zoals vroeger (maecken, leeren worden nu gespeld als maken, leren).
Maar dat verklaart nog niet het verschil in woordlengte tussen de oude kranten: wat zou de reden kunnen zijn dat de Nieuwe Tijdinghen systematisch meer types met woordlengte 1 tot en met 8 hebben dan het Couranten Corpus, terwijl de balans daarna omslaat? (Op tokenniveau is het verschil nauwelijks nog zichtbaar). En wat veroorzaakt het dipje bij woordlengte 7 in het Couranten Corpus? Mijn hypothese is dat het verschil het gevolg is van de e-apocope, het wegvallen van de onbeklemtoonde slot-e, die in deze periode met name in het Hollands plaatsvond. Christiaan van Heule schreef hierover in De Nederduytsche Grammatica ofte Spraec-konst uit 1625 (p. 91):
“In Hollant worden de woorden in het uytspreeken zeer verkort, zo dat bynae alle woorden in het eenvoudigh [enkelvoud] zonder E op het eynde uytgesprooken worden, zeggende Vraeg, Antwoort, Ik zeg, Ik heb, in de plaetse van Vraege, Antwoorde, Zegge, hebbe.”
Die Hollandse verkorting betreft in principe alle woordlengtes. Om de hypothese te toetsen heb ik bekeken of er een systematisch verschil bestaat tussen het aantal woorden (types) op -e in de Amsterdamse kranten en in de Nieuwe Tijdinghen. Ik heb daarvoor het percentage woorden op -e per woordlengte afgezet tegen het totale aantal woorden met diezelfde woordlengte. Het resultaat is te vinden in Figuur 6. Woordlengte 1, 2 of 3 kunnen niet worden verkort of leveren te veel ruis op, denk aan de vele niet relevante functiewoorden op -e als de, die, ene, toe, wie, hoe, nae, ghe, uwe, jae etc; die woordlengte heb ik dus genegeerd.
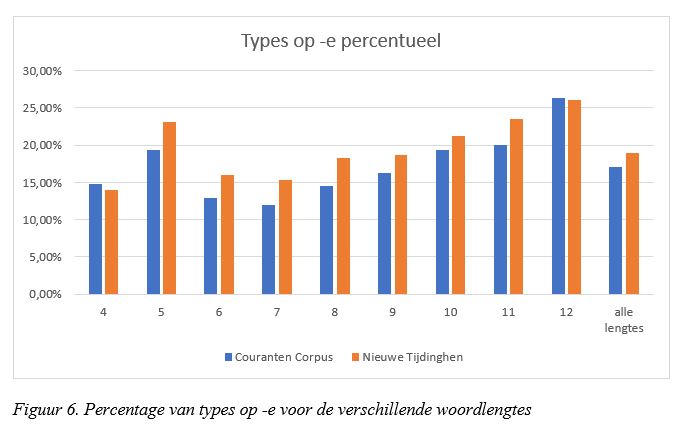
Het blijkt dat de Nieuwe Tijdinghen voor alle woordlengtes van 5 tot en met 11 procentueel gezien meer woorden op -e heeft dan het Couranten Corpus, en dat datzelfde ook geldt voor het totale aantal types (van alle woordlengtes). Alleen voor woordlengte 4 gaat de regel niet op, maar woorden van die lengte kunnen ook slechts moeilijk verkort worden, en bij woordlengte 12 verdwijnt het effect. Figuur 6 lijkt aan te tonen dat de Hollandse e-apocope er inderdaad mede toe heeft geleid dat het Couranten Corpus minder types heeft met woordlengte 6, 7 en 8 dan de Nieuwe Tijdinghen (zoals bleek in Figuur 4).
In de moderne kranten is de Hollandse e-apocope inmiddels voltrokken, met als gevolg dat het hoogtepunt van de curve telkens bij een eerdere woordlengte valt dan die bij de oudere kranten: bij de types op woordlengte 7 (in plaats van 8) en bij de tokens op woordlengte 2 en 3 (in plaats van 3 en 4).
Daarmee is nog niet het dipje bij de types met woordlengte 7 in het Couranten Corpus verklaard, dat correspondeert met een dipje in de tokens met woordlengte 6 in de moderne kranten en een stilstand op die plek in de daling in het Courantencorpus. Ik vermoed dat dat dipje wordt veroorzaakt door de stap van simplex naar samenstelling of afleiding (inclusief verkleinwoord of meervoudsvorm): simplexen zijn per definitie kort en vaak eenlettergrepig, samenstellingen en afleidingen zijn lang(er), en het verschil wordt meestal gevormd door meer dan 1 letter, waardoor er op de scheiding tussen simplexen en afleidingen/samenstellingen een hiaat ontstaat.
Via wat eenvoudige computertellingen kun je dus verschillen in taalgebruik en taalveranderingen op het spoor komen. Het zoeken naar de oorzaken daarvan blijft voorlopig nog mensenwerk, gelukkig.
Literatuur
Ampzing, Samuel (1628). Nederlandsch Tael-bericht, in: Zwaan, F.L. (1939), Uit de geschiedenis der Nederlandsche spraakkunst, Groningen/Batavia, pp. 133-191.
Sigurd, Bengt, Mats Eeg-Olofsson & Joost van de Weijer, ‘Word length, sentence length and frequency – zipf revisited’, in: Studia Linguistica 58(1) 2004, pp. 37–52.
Sijs, Nicoline van der (2021), Taalwetten maken en vinden: het ontstaan van het Standaardnederlands, Gorredijk.
U schrijft: “Een woord als augustus spreken we al lange tijd uit als oogst”
Ik zit al minuten lang naar die zin te kijken en probeer augustus uit te spreken als oogst maar dat lukt mij niet en eerlijk gezegd heb ik ik het nog nooit gehoord.
Is dit een regionaal fenomeen, alleen bij Amsterdammers of zo? Heb ik iets gemist of – en dat hoop ik maar – is er iets misgegaan bij het schrijven van die zin?
sorry, misschien wat te kort door de bocht geformuleerd, maar zie: https://etymologiebank.nl/trefwoord/oogst