Door Gerrit Bloothooft
We leren en leven door na te doen en zijn zelden origineel. Dat is misschien wel zo rustig want stel je voor dat we allemaal een unieke voornaam zouden hebben. Hoe we nadoen en kopiëren is trouwens boeiend genoeg. Het is de sleutel om te begrijpen hoe vernieuwingen breed navolging kunnen vinden, of juist niet. De kern van mijn eerdere betogen was dat wanneer ouders een kind een voornaam geven, dat een effect op anderen heeft. Die vormen de sociale omgeving in de breedste zin. Niet alleen familie en vrienden, maar ook buren, collega’s, andere ouders op school enzovoort. Als daar ouders bij zijn die een kind verwachten, dan zouden die het een mooie naam kunnen vinden en er ook voor kunnen kiezen. Bij nieuwe namen – ze worden toch wel eens geïntroduceerd – is dat navolgingsproces goed te bestuderen. Ik dacht eerst dat zo’n proces niet van de nieuwe naam zou afhangen, maar vond dat voornamen die later populair blijken te worden al onmiddellijk na de introductie veel sneller nagevolgd worden. Dat ga ik hier verder uitwerken. Ik haal in figuur 1 eerst een grafiek terug uit aflevering 8, waarin de kans staat hoe lang het duurt voordat een naam een tweede keer wordt gegeven (voor 16.516 nieuwe voornamen uit de periode 1920 en 1960 die tot 2014 minstens twee keer zijn gegeven). Deze kans neemt exponentieel af met de tijd. Er zijn namen die vrij snel overgenomen worden door andere ouders, maar ook (minder) namen waarbij het tientallen jaren kan duren. Op deze figuur kwam de reactie dat de benadering met zo’n exponentiële functie niet zo goed was. Dat is juist en dat komt omdat de kans afhankelijk blijkt van de latere populariteit van de naam, en die differentiatie is in figuur 1 nog niet gemaakt. Ik beloofde dat goed te maken, en ga dat hier doen.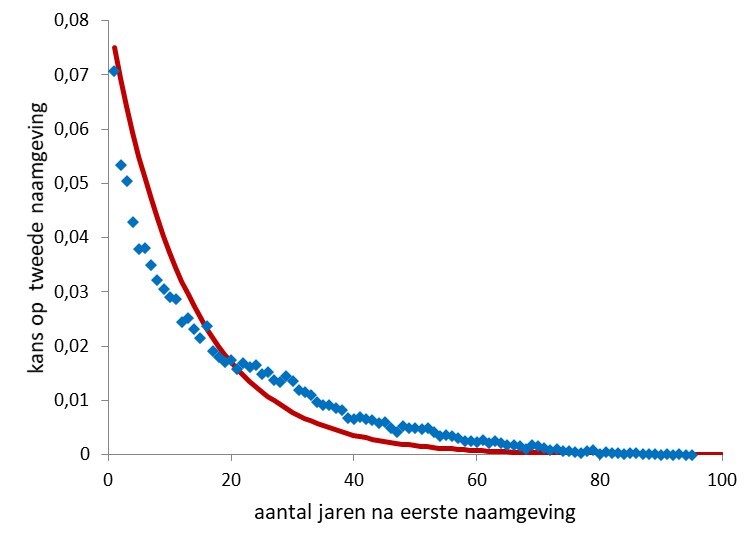
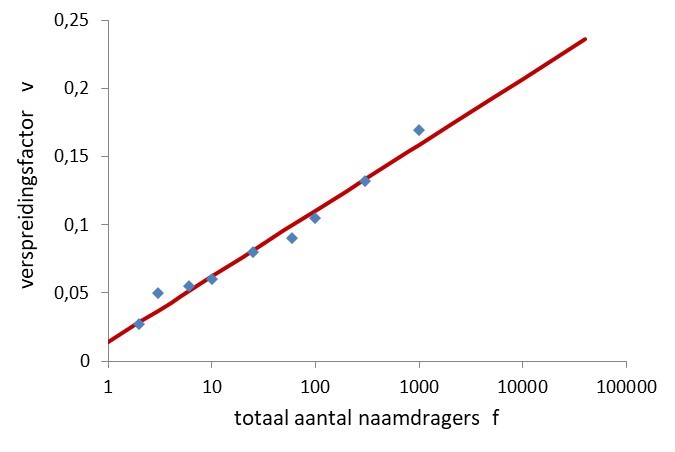
- Ik verwachtte dat voor een unieke naam v(1)=0 zou moeten worden, want er is geen verspreiding. Maar er is voor een goede benadering vanaf f=2 toch een kleine constante nodig.
- De waarden voor figuur 2 zijn afgeleid uit benaderingen voor p1,k(j) [k=2,3,10,100,500] voor namen met 2, 3 tot 10, 11 tot 100, 101 tot 500, en meer dan 500 naamdragers, zie aflevering 11. De formule voor v(f) is iets preciezer dan die in de opmerkingen bij aflevering 15 wordt gegeven.
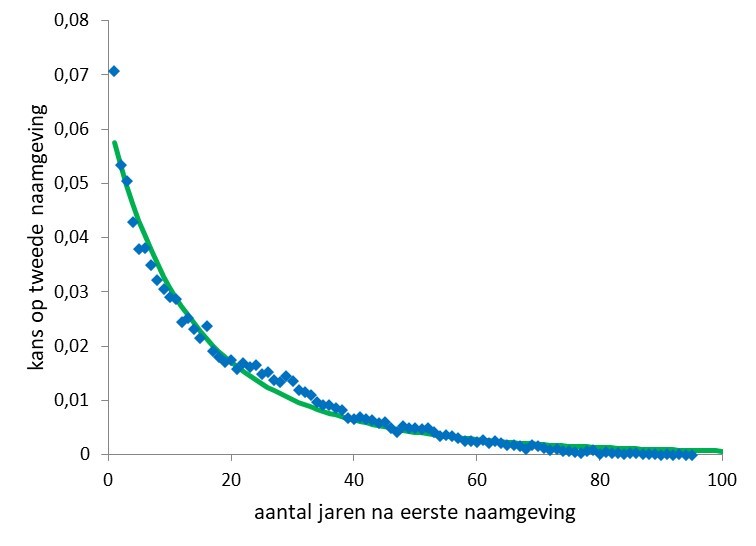
- De benadering in figuur 3 is gemaakt voor alle naamfrequenties tussen 2 en 1000.
α = -1,57
dat zou wel eens A*pi kunnen wezen, A = – 1/2