Dagboek van een amateur-programmeur

Nu we hier zo gezellig thuis zitten, en Ewoud Sanders zo vrijgevig is geweest met een paar grote bestanden met pdf’s, leek het me aardig om daar nog eens wat verder in te zoeken. Dit wordt hopelijk het begin van een serietje, want ik denk dat ik meteen iets op het spoor ben en het is misschien een aardige manier om jullie mee te laten leven met dit onderzoek – dat op dit moment nog maar aan het begin staat.
Ik nam Ewouds collectie van ‘streekromans’, boeken uit het genre van de zogeheten ‘lagere literatuur’, Zoals hij zelf zegt, is dit genre nauwelijks onderzocht, en ik zou zeggen: zeker de teksten niet. Er is wel wat aandacht voor dit soort boeken en hun schrijvers, maar die aandacht is naar mijn indruk toch vooral sociologisch (wie lezen zulke boeken). Naar de teksten is nog niet veel gekeken en niet veel naar hun taalgebruik.
In een ander stukje van afgelopen donderdag beschrijft Ewoud welke methoden hij gebruikt voor het doorzoeken van dit soort bestanden. Hij is een zeer ervaren zoeker dus hij geeft waardevolle tips over welke bestaande software te gebruiken, Maar ik wil nog iets meer hobbyen, en heb dus zelf een paar scripts in elkaar gedraaid; die kunnen niet hetzelfde als wat Ewouds programma’s kunnen – met name zijn ze niet zo efficiënt in het doorzoeken. Maar als je alles zelf doet, kun je wel flexibeler zijn.
Ik heb mijn scripts geschreven in Python en op mijn Github-account gezet. Het eerste script (leesfiles), maakt een overzicht van de frequentste nomina in iedere roman en zet deze in een grafiekje. Hier is er bijvoorbeeld een voor een omnibus van Eens komt de dag van Leni Saris:

Het scriptje werkt rechttoe-rechtaan: het haalt eerst de tekst uit de pdf, en gebruikt dan bestaande pakketten voor taalanalyse om te bepalen of een woord een zelfstandig naamwoord is, telt hoe vaak ieder woord voorkomt, en zet die in een grafiek. (Ja, tamelijk rechttoe-rechtaan, maar het is moeilijk om ergens een pakket te kopen dat al die dingen kan.)
Behalve dat het, weinig verrassend, een Zipf-achtige verdeling geeft en dat er nog wat troep in zit (de genitief-s wordt door mijn script als een apart nomen beschouwd, dat kennelijk heel frequent is, zie je hier iets dat je bij bijna alle grafieken voor bijna alle romans ziet: dat er enorm veel namen in de top-10 staan.
Omdat de precieze hoeveelheid keren dat individuele vormen voorkomen me in dit geval niet zo interesseert, heb ik vervolgens met een andere script ‘wordclouds’ gemaakt, die hetzelfde laten zien. Roman na roman besteedt grote aandacht aan voornamen (de aandachtige beschouwer ziet overigens dat ik in dit geval niet alleen maar kijk naar zelfstandig naamwoorden – maar zelfs in dat geval zijn namen duidelijk nog heel dominant):
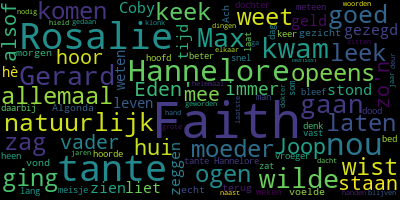

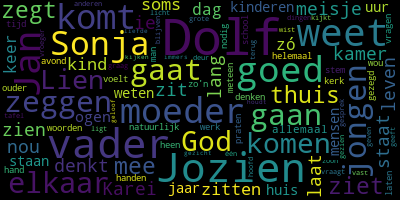
Zo te zien maakt de tijd waarin boeken verschenen zijn niet zoveel uit: in al deze boeken zijn namen zeer frequent. Nu rijst de hypothese dat deze hoge frequentie van eigennamen misschien wel kenmerkend is voor dit genre. Dat wil ik gaan onderzoeken in een vergelijking met een aantal ‘literaire’ romans, als ik die ook als pdf’s kan krijgen.
Maar daarvoor moet ik natuurlijk geen individuele namen gaan tellen, want dat schiet niet op: er komen in verschillende romans verschillende namen voor. Dus ik moet eerst ervoor gaan zorgen dat de computer namen als namen herkent. In de volgende aflevering leg ik uit hoe ik dat doe (hoop ik, want ik heb het nog niet gedaan).
De volgende stap is dan om dat te vergelijken met wat er gebeurt in die literaire romans, en dan eigenlijk op twee niveaus: worden er in streekromans inderdaad meer namen gebruikt? En zijn dat ook andere namen en wat verklaart dat dan? Een simpele hypothese is dat het over namen zou gaan die voorkomen in lagere sociale milieus, maar klopt dat wel?
“Dus ik moet eerst ervoor gaan zorgen dat de computer namen als namen herkent. In de volgende aflevering leg ik uit hoe ik dat doe (hoop ik, want ik heb het nog niet gedaan).”
Mijn suggestie zou zijn om de computer een lijst met namen te voeren. Jozien, Dolf en Sonja zijn in elk geval allemaal bestaande namen. Als ik me niet vergis schreef Gerrit Bloothooft hier eerder over een corpus van roepnamen (uit rouwadvertenties).
Verder is het misschien zo dat veel eigennamen niet een eigenschap is van streekromans, maar dat weinig eigennamen een eigenschap is van niet-streekromans. Hogere romanciers schrijven meer met dichtgeknepen billen / minder spontaan.
Toevoeging bij mijn opmerking hierboven: mijn voorstel zal geen efficiënte manier zijn voor het herkennen van eigennamen. Maar je kunt met zo’n rouwadvertentie- of geboorteadvertentiecorpus (als dat idd beschikbaar is) wel allerlei informatie over de status en herkomst van de naamdragers vinden. Ik kan me ook voorstellen dat streekromanciers bewust of onbewust namen kiezen die ‘streeks’ klinken, zoals vrouwennamen op -ien.
Omgekeerd kan een rouwadvertentie/geboorteadvertentie-corpus misschien beschikbaar worden gesteld aan streekromanciers, zodat zij hun namen realistisch kunnen kiezen.
Eigennamen zijn eenvoudig te herkennen aan de Hoofdletter. (Marc vouwt alles naar lowercase, dus dat istie kwijt)
Veder hebben eigennamen in de grammatica vaak de zelfde plaats/rol als [lidwoord+zelfstandig naamwoord]. Maar dan heb je (een beperkte vorm van) PoS-tagging nodig.
@James Sjaalman,
PoS-taging zal niet het probleem zijn, maar met hoofletters als aanvullend criterium krijg je ook geografische namen erbij, zoals in: ‘Wat is Driel toch een heerlijke woonplek.’ Je zult tekstinhoudelijke dingen moeten gebruiken. Mogelijk kun je er op gokken dat een eigennaam bijna altijd een keer in combinatie met ‘zegt’ of ‘zei’ (‘liep’, ‘dacht’, etc.) wordt gebruikt in een roman: ‘Ach wat heerlijk is het toch in Driel, zei Josien.’ Voor de frequentie-hypothese zou dat voldoende kunnen zijn, ook omdat je met grachtengordelromans kunt vergelijken.
Nog een punt: waarschijnlijk speelt de typografische traditie een belangrijke rol. Veel typografen van hogere uitgevers typograferen dialoog met kastlijntjes. Dan hoef je de naam er minder vaak bij te noemen, omdat de rolwisseling uit de opmaak volgt. Je zou dus ook de kastlijntjes aan het begin van regels moeten tellen.