Lezen is niet alleen een van de leukste dingen die je brein kan doen, het is ook enorm ingewikkeld. Van alles en nog wat komt erbij kijken: begrip van de taal, manieren om bij te houden waar je precies bent in een verhaal of een betoog, je stelt je misschien visueel voor wat je ziet, je reageert emotioneel en wat al niet.
Maar daarbij is lezen uiteindelijk ook nog een vorm van kijken. Je ziet de lettervormen op het papier, identificeert ze, vergelijkt ze met andere letters die je eerder hebt gezien – zelfs voor een geheel nieuw lettertype is dat doorgaans geen probleem. Met een beetje ervaring herken je zelfs woorden in één oogopslag.
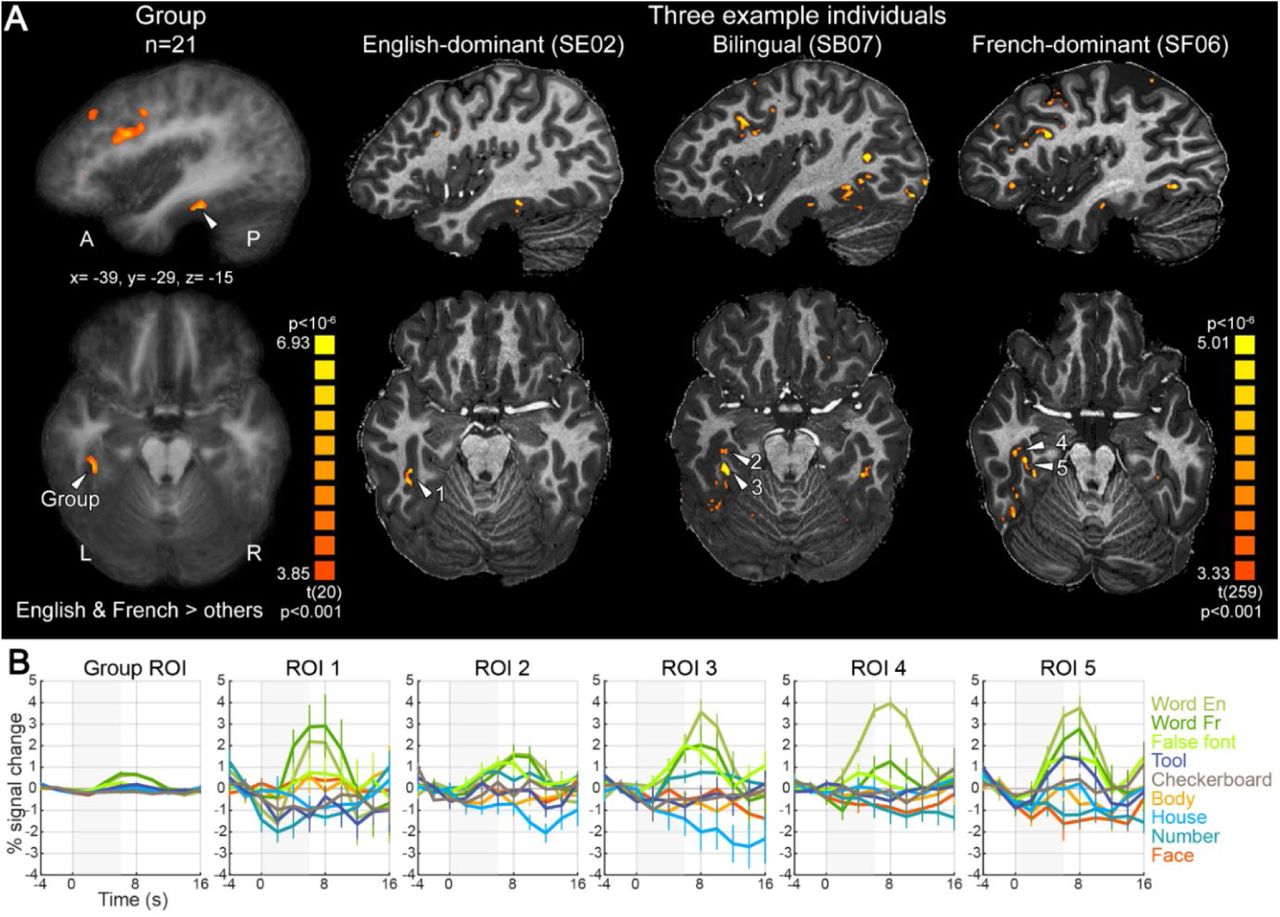
Over het lezen op dat, laten we zeggen, allerlaagste niveau doet de Franse onderzoeker Stanislas Dehaene met zijn Parijse medewerkers al langere tijd fascinerend onderzoek. Deze week verscheen er een nieuw, nog niet gepubliceerd artikel (een preprint) op de website Biorxiv.
Gezichtsherkenning
In dit artikel vergelijken de onderzoekers hoe tweetalige lezers lezen: gebruiken ze daarvoor dezelfde hersendelen? We weten dat voor het lezen bepaalde ‘visuele’ delen van de hersenen worden ‘hergebruikt’ – dit geldt met name voor de hersendelen die we anders gebruiken om 3D te zien. Bovendien weten we dat iedereen voor het lezen in grote lijnen dezelfde delen van de hersenen gebruikt – zelfs onafhankelijk van het schriftsysteem, dus of het nu over karakters gaat, Arabische letters of het Latijnse alfabet. Kennelijk is dat een gebied van de hersenen waar het goed mee gaat. (In eerder werk heeft Dehaene laten zien dat dit mogelijk gebruikt dat die heel verschillende schriftsystemen bestaan uit soortgelijke elementen, die makkelijk opgepikt worden door het visuele deel van de hersenen dat verantwoordelijk is om diepte te zien.)
In hun nieuwe onderzoek keken de onderzoekers naar twee groepen: tweetaligen in het Engels en het Frans en tweetaligen in het Chinees en het Engels. Die twee groepen kunnen bijna niet verder uit elkaar lijken. Engels en Frans hebben niet alleen hetzelfde alfabet, maar omdat het Engels veel woorden uit het Frans heeft geleend (beauty, joy) en beide talen een conservatieve spelling hebben, lijken veel woorden visueel ook nog op elkaar (beauté, joie). Aan de andere kant zijn het Chinees en het Engels heel verschillende talen die ook nog gebruik maken van heel verschillende schriftsystemen.
Het is misschien ook niet verrassend dat Frans-Engels tweetaligen echt hetzelfde hersendeel gebruikten om de twee talen te lezen, maar bij de tweetaligen in het Chinees en het Engels was er ook een enorme overlap. De verschillen waren zelfs maar heel klein en betroffen vooral dat deze lezers iets meer geneigd waren om voor het Chinees ook een ander deeltje van de hersenen erbij te betrekken – het deel dat we evolutionair gezien gebruiken om gezichten te herkennen. Ze deden dat, als ik de resultaten goed interpreteer, zelfs meer dan een eentalige Chinezen. Die gezichtsherkenning is dus een hulptroep die wordt ingeschakeld om zaken een beetje uit elkaar te houden.
Deze reactie is niet zo flauw bedoeld als het lijkt. Toen ik de titel las, dacht ik: Ik lees vaak in bed! Waar het in het artikel écht over gaat, is daardoor misschien nog wel interessanter voor me geworden…
Misschien is de vraag wel: wie lees er hier, ik of het brein. Nog interessanter is dat het hele brein leest en dus niet alleen de gebieden die oplichten. Zelfs als je zaken uit elkaar wil houden.