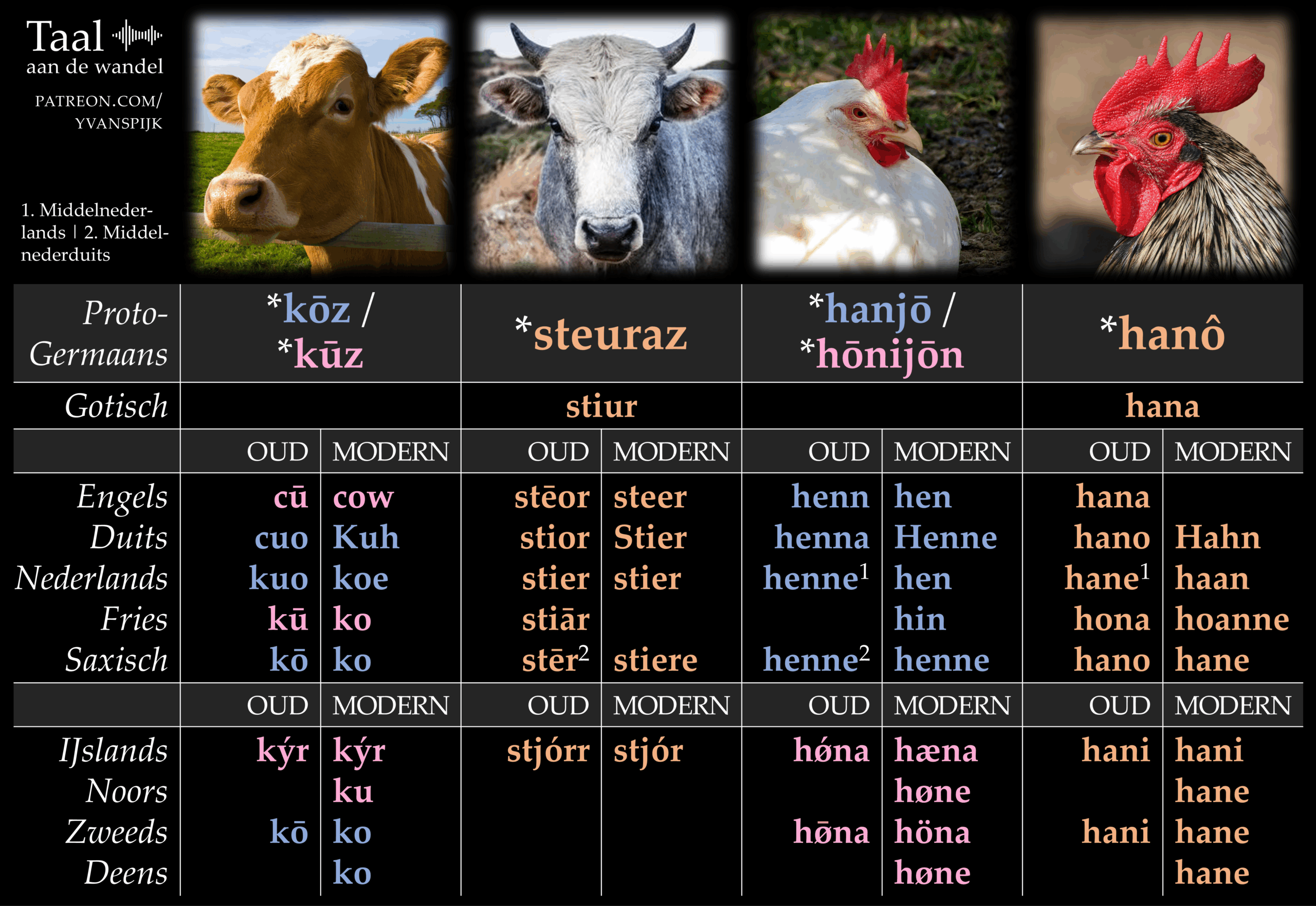
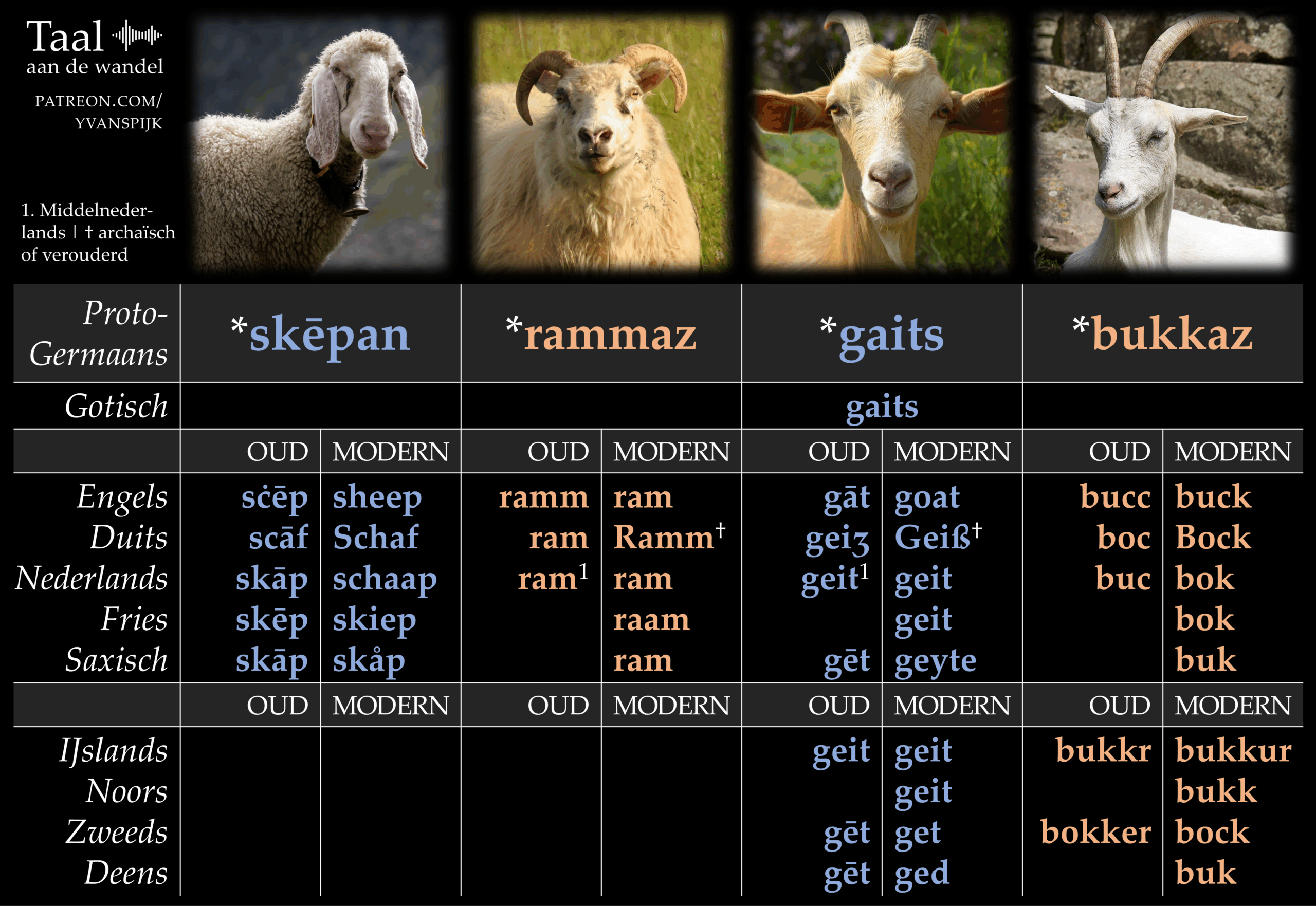
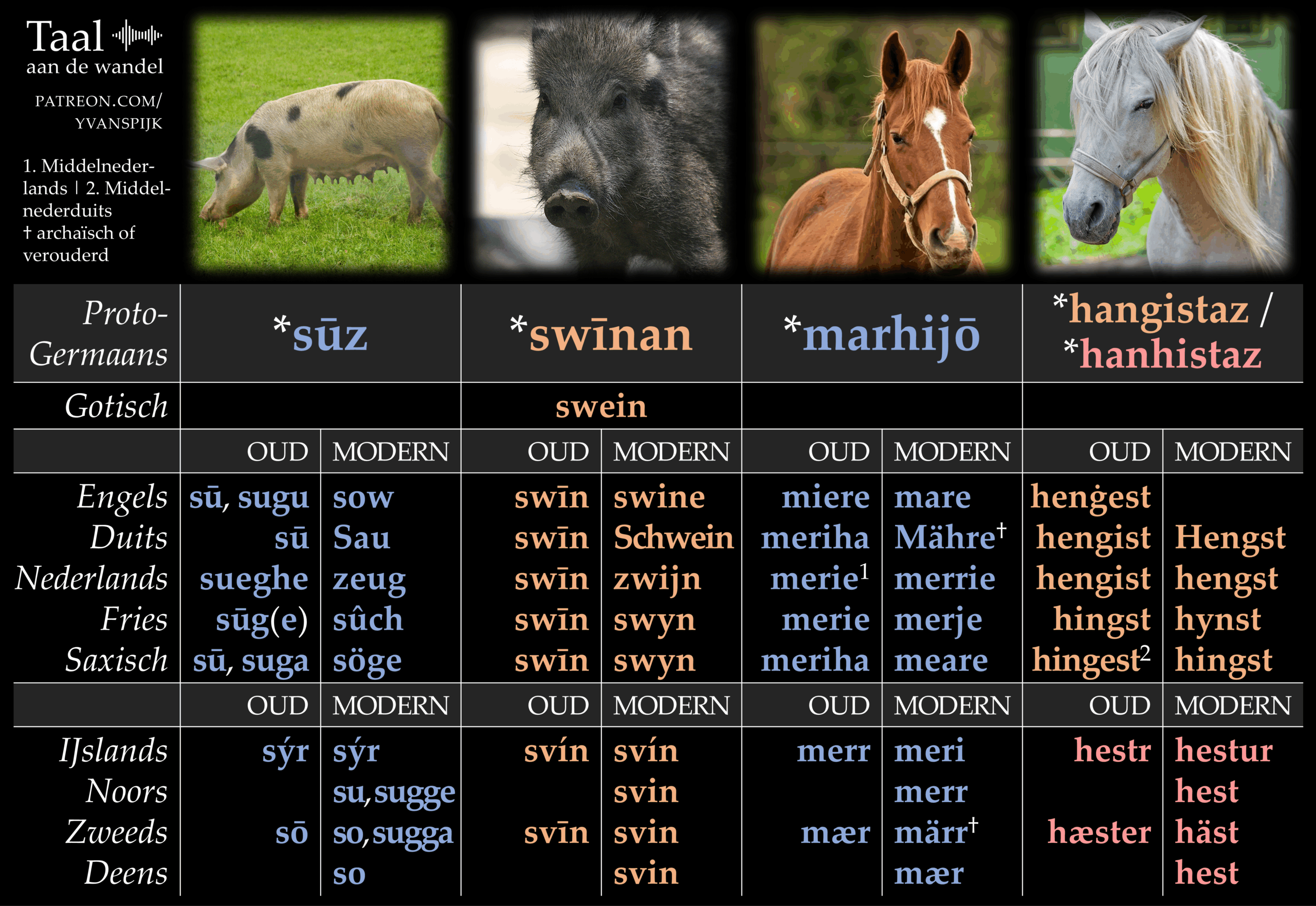
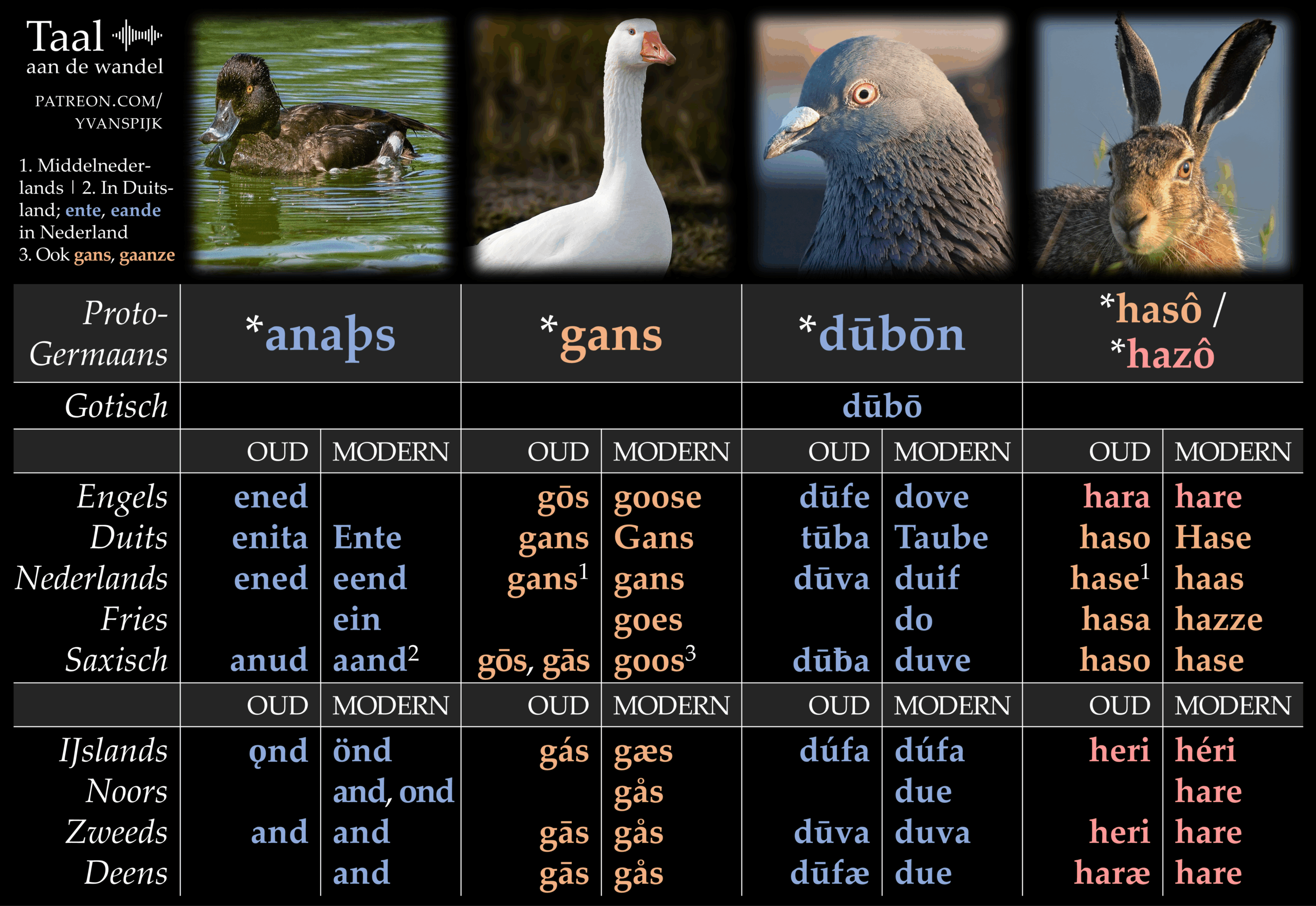
Tweeduizend jaar geleden waren er natuurlijk nog geen kinderboerderijen, maar de woorden voor de dieren die je in die minidierentuinen vindt, bestonden toen al. Ze zagen er alleen nog heel anders uit. In dit artikel vind je vier infographics, die de Proto-Germaanse reconstructies tonen van zestien woorden voor dieren. En dat niet alleen: je ziet op deze afbeeldingen ook de nazaten in de tien grootste Germaanse talen – in hun huidige vorm én hun middeleeuwse.
Een noot vooraf: de vier afbeeldingen zijn gericht op de etymologie. Welke nazaten heeft bijvoorbeeld het Proto-Germaanse *steuraz (‘stier’) gekregen? De woorden die je ziet in de moderne taalfases, zijn dus niet per se de huidige woorden voor dat dier. Na de vier afbeeldingen vertel ik meer over deze kwestie en andere aspecten.
Etymologie als uitgangspunt
Het Nedersaksische stiere is zo’n woord dat puur om etymologische redenen op de afbeelding staat. Stiere bestaat nog maar in enkele dialecten van het Nedersaksisch, zoals sommige Drentse, en waar het voorkomt, is het niet het meestgebruikte woord. Dat is in de meeste regio’s bolle, dat verwant is aan het Friese bulle, het Engelse bull en het Nederlandse bul.
Sommige woorden hebben tegenwoordig een net iets andere betekenis. Het Oudzweedse hæster betekende bijvoorbeeld nog ‘hengst’, maar het hedendaagse häst is gewoon ‘paard’ geworden. Het woord staat toch in de kolom van ‘hengst’ omdat het verwant is aan ons hengst.
De woorden met een kruisje erachter hebben ook wat uitleg nodig. Die zijn namelijk aan het verouderen of ze zijn al helemaal verouderd. Het Duitse Ramm, Geiß en Mähre worden nog vermeld in de woordenboeken, maar in het dagelijks leven zul je mensen in de meeste delen van het Duitse taalgebied Schafbock, Ziege en Stute horen zeggen.
Lege regels
Waar je een lege regel ziet in de kolom oud, is het woord niet aangetroffen. Dat wil niet zeggen dat het niet bestond: het staat simpelweg niet in de teksten die dankzij ijverig monnikenwerk aan ons overgeleverd zijn. Het Friese woord voor ‘duif’, do, moet een Oudfriese voorouder hebben gehad, maar in het Oudfriese tekstcorpus, dat vooral uit rechtsteksten bestaat, wordt toevallig niet over duiven gesproken.
Een lege regel in de kolom modern wil zeggen dat het woord is uitgestorven. Het Oudengelse hana kreeg concurrentie van andere woorden en heeft het uiteindelijk afgelegd tegen cock en rooster. Als het was blijven bestaan, hadden we nu *hane gehad, maar dat is puur hypothetisch.
Je ziet dat de kolommen voor ‘schaap’ en ‘ram’ helemaal leeg zijn bij de Noordgermaanse talen. Dat komt doordat die talen sinds het begin van de overlevering heel andere woorden gebruiken. ‘Schaap’ is in het Zweeds bijvoorbeeld får, van het Proto-Germaanse *fahaz (‘schaap’), en ‘stier’ is tjur, van het Proto-Germaanse *þeuraz (met *þ als th-klank die uit een eerdere *t ontstond). Mogelijk was dat een s-loze variant van *steuraz, de voorloper van stier.
Hoe komen we aan zeug?
De derde afbeelding laat zien dat ons woord zeug van het Proto-Germaanse *sūz komt, maar dat woord had geen g. Hoe komen wij dan aan onze g in zeug?
De g van zeug – en die van enkele tegenhangers in zustertalen – is ontstaan uit een w. Die w zat in tien van de twaalf naamvallen van *sūz, zoals *suwun (de vierde naamval enkelvoud) en *suwiz (‘zeugen’, de eerste naamval meervoud). Toen die w een g werd, had de meerderheid van naamvallen dus voortaan een g. In het West-Germaans ontstond er vervolgens een variant van het woord waarin de g doorgetrokken werd naar álle naamvallen. Daar stamt zeug van af.
Zeug is niet het enige woord met een g die van een w komt. Ons woord jeugd gaat bijvoorbeeld terug op het Proto-Germaanse *juwunþiz met een w, en negen komt van *newun. Ook in deze gevallen is het Nederlands niet uniek. In het Oudengels hadden youth en nine namelijk nog de vormen ġeoguþ (uitspraak: /joegoeth/, IPA [juɣuθ]) en nigon, ook met een g. Denk ook aan het Duitse Jugend – terwijl neun dan weer g-loos is gebleven.
Van w naar g
Maar hoe ontstaat een g uit een w? In het Germaans en de oude dochtertalen lagen die klanken vrij dicht bij elkaar. De w moet toen namelijk nog uitgesproken zijn geweest zoals nu nog steeds in het Engels. Zo’n w heeft twee belangrijke kenmerken. Hij is ten eerste bilabiaal – dat wil zeggen: je spreekt hem uit met beide lippen, dus niet met de voortanden op de onderlippen zoals boven de grote Nederlandse rivieren.
De ‘Engelse’ w is daarnaast velair. Dat betekent dat je je tong wat optilt naar je zachte gehemelte, oftewel het velum. Dat geeft er die donkere, oe-achtige klank aan – die overigens ontbreekt beneden de rivieren.
Reconstructie wijst erop dat de g in het oude Germaans ook velair was. Het was dus nog niet de huigrochel – in taalkundige termen uvulaire wrijfklank – die je nu vooral in de Randstad hoort. De g tussen klinkers wordt voor het Proto-Germaans (en de middeleeuwse dochtertalen, behalve het Duits) gereconstrueerd als een velaire wrijfklank. Die lijkt nog het meest op de Brabantse g in ogen (die, voor de fijnproevers, ietsjes anders is: prevelair).
De Germaanse velaire w en g hadden dus veel overeenkomsten. Hieronder hoor je een reconstructie van hoe *suwun in *sugun moet zijn veranderd:
De w– en g-loze vorm *sūz bleef overigens ook voortbestaan in enkele talen. Hij verloor zijn *z en werd via bijvoorbeeld het Oudhoogduitse sū het hedendaagse Sau. Bij ons zou er *zui uit gekomen zijn.
Hoe klonken de woorden op de afbeeldingen?
Hoe zouden de Proto-Germaanse woorden en hun middeleeuwse nazaten geklonken hebben? Een van mijn favoriete aspecten van de historische taalkunde is klankreconstructie. Nee, we hebben inderdaad geen opnames uit de Germaanse ijzertijd en de middeleeuwen, maar dankzij een vorm van taalkundige paleontologie weten we aardig wat over de historische uitspraak.
Wekelijks deel ik op mijn sociale media twee infographics, zoals hier op Tumblr en hier op Bluesky. Liefhebbers van mijn werk kunnen ervoor kiezen om me maandelijks met een klein geldbedrag te steunen op het platform Patreon, en daar krijgen ze wat extra’s voor. Voor € 2 per maand kunnen ze bij ongeveer 60% van de posts een kort Engelstalig artikel vinden, en bij € 5 krijgen ze bij elke infographic een audiobestand. Daarin laat ik horen wat de reconstructies zijn van de historische Romaanse en Germaanse woorden die op de afbeelding staan, van het Latijn tot het Oudspaans en van het Proto-Germaans tot het Oudfries.
Zo heb ik ook de 103 historische en gereconstrueerde woorden opgenomen die je op de vier infographics van vandaag vindt. In 3,5 minuut hoor je ze allemaal voorbijkomen. Hou je niet van abonnementen, dan kun je hier ook toegang krijgen tot dit audiobestand voor de eenmalige prijs van € 3.
Waarom een betaalmuur?
Mijn infographics zullen altijd gratis blijven. Ik ben er in 2020 mee begonnen met één doel: mensen enthousiast maken over de historische taalkunde.
We zijn nu zo’n 300 infographics verder en ik ben er steeds meer tijd in gaan steken. Wekelijks twee infographics maken kost me algauw zo’n zes tot acht uur. Toen sommige van mijn volgers op de sociale media me in 2023 lieten weten dat ze me wilden steunen met een kleine bijdrage, heb ik een Patreon-account aangemaakt. In ruil voor hun steun krijgen ze wat extra’s. Intussen heb ik 101 patrons.
Mensen die me voor € 5 willen sponsoren, geef ik dat extraatje in de vorm van de opnames. Die kosten ook weer extra tijd: uitzoeken, inspreken en nabewerken. Vandaar dat ik dat werk niet gratis beschikbaar stel. Op mijn YouTube-kanaal vind je meer dan vijftig gratis video’s met uitspraakreconstructies.
Bron afbeeldingen: Wikimedia Commons
Dit stuk verscheen eerder op Taal aan de wandel.
Laat een reactie achter