De vraag hoe mensenkinderen taal leren, heeft misschien wel nieuwe impulsen gekregen door de komst van grotetaalmodellen. Tot een paar jaar geleden kon je nog tegen iedereen zeggen dat mensen de enigen waren die in staat waren tot zoiets. Nu kijken mensen je verbaasd aan en zeggen ‘maar ChatGPT dan?’ Want inderdaad kunnen chatbots nu bepaalde dingen die we vroeger als uitingen van taalvaardigheid zaten: stukken schrijven, chatten met gebruikers, wezenloze podcasts maken.
En op de een of andere manier hebben ze dat geleerd.
Zoals de dingen dan gaan, betekent zo’n technologie een herdefinitie van wat het betekent om menselijk te zijn. De kern van menselijke taal is misschien niet gelegen in het schrijven van artikelen, maar in het voeren van een spontaan gesprek, met alle aarzelingen, vergissingen, aanrakingen en lichaamstaal die daarbij horen. Mensen zijn goede taalleerders omdat ze zo efficiënt zijn: als de mens net zoveel materiaal nodig had als een chatbot om te leren praten was hij 92.000 jaar bezig.
Niet genoeg
Er zijn, in de langdurige discussie over menselijke taalverwerving, twee uitersten. De ene is nativistisch: die zegt dat we worden geboren met een biologisch programma dat stap voor stap bepaalt hoe onze taal zich ontwikkelt – als je mensen ik loop hoort zeggen, is dat een aanwijzing om als stapje in dat programma vast te stellen dat in de taal van jou omgeving onderwerpen voor werkwoorden staan. Dat feit wordt dan ingekapseld in een aangeboren kennis in hoe taal werkt. De andere is empiristisch: die zegt dat je geboren wordt als een blanko blad – je slaat alleen voortdurend alles op wat je hoort, voert daar een soort biologische statistiek op uit, en daar komt dan de rommelige grammatica van je moedertaal uit rollen.
Beide extreme modellen zijn onwaarschijnlijk. Tegen het nativisme kun je inbrengen dat taalkundig onderzoek wel heel veel verschillen tussen talen aan de oppervlakte heeft gebracht in grammatica en in klankvorm en die moeten kinderen allemaal leren. Overeenkomsten tussen talen zijn er volgens sommigen – ik hoor daar bij – ook wel, maar die zijn nogal abstract: dat je om uit te rekenen of een zin goed in elkaar zit precies een bepaalde soort rekenkracht nodig hebt. Dat is dus iets wat je niet hoeft te leren, maar precies op dat heel abstracte niveau lijken talen dus op elkaar. Tegen strikt empirisme kun je het argument inbrengen van die chatbots – die hebben irreëel veel gegevens nodig om tot de juiste conclusie te komen – en ook dat kinderen duidelijk geboren worden met een heel duidelijk idee over wat taal is – vlak na de geboorte luisteren ze bijvoorbeeld al intensiever naar een geluidsopname waarop iemand praat dan naar dezelfde geluidsopname als deze achterstevoren wordt gedraaid. Dat klinkt niet genoeg als taal.
Oplossing
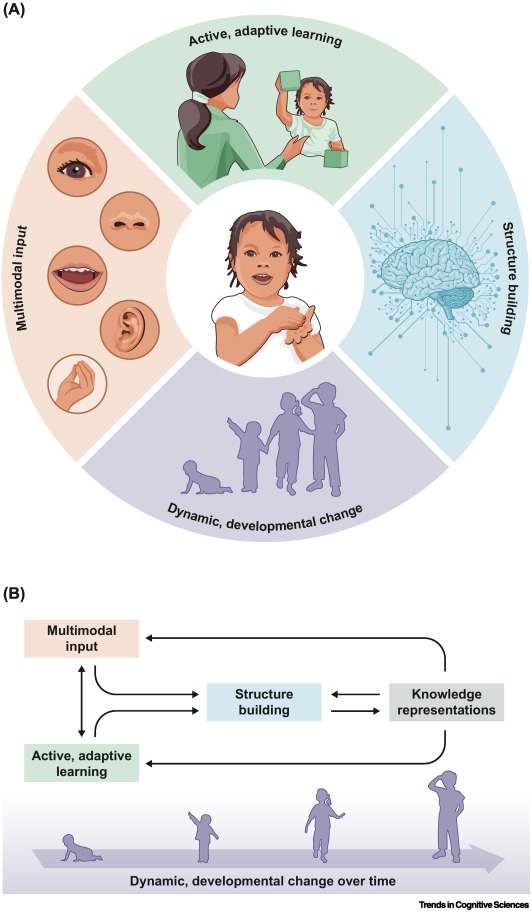
Er is dus een middenweg nodig. In een artikel in Trends in Cognitive Science proberen Caroline Rowland van het Max Planck Instituut en een aantal van haar collega’s zo’n model te schetsen. Constructivisme noemen ze dat: jonge kinderen zijn volgens dat model een soort kleine taalwetenschappers. Ze proberen door intensief te luisteren en te kijken én door te observeren hoe mensen reageren op wat ze zeggen een theorie te construeren. Die theorie wordt misschien deels geïnformeerd door wat ze verwachten dat taal is (omgekeerd praten, dat is geen taal) en deels beperkt door wat menselijke hersenen nu eenmaal aankunnen (tijdens het praten moet je razendsnel zijn en dan kun je alleen bepaalde beperkingen aan).
Het is een model dat heel anders is dan hoe taalmodellen werken. Die zijn niet erg actief en absorberen vooralsnog alleen wat ze toegediend krijgen. Het is ook geen heel nieuw model: Rowland en haar collega’s verwijzen zelf naar Jean Piaget (1896-1980) als een voorloper van hun vorm van ‘constructivisme’. Tegelijkertijd is het model ook zeker nog niet uitgewerkt: zoveel dingen moet een kind leren als het taal leert (klanken, grammatica, woorden, hoe om te gaan met je gesprekspartners, enz.) en zoveel is er wat dat betreft nog onduidelijk dat we voorlopig nog geen volledig beeld hebben.
Tenzij een chatbot eerdaags een oplossing vindt, natuurlijk.
“Mensen zijn goede taalleerders omdat ze zo efficiënt zijn”
Het is krek zo. En Bennie Mols maakt in zijn boekje over A.I., “Slim, slimmer, slimst”, de pertinente observatie dat mensen ook efficiënt zijn in hun energiegebruik. Om te leren wat ze allemaal leren, hebben kinderen nog geen fractie aan energie nodig die de computers nodig hebben.
Dat over achterstevorentaal zegt niets. Het laat alleen zien dat een kind voor de geboorte al iets geleerd heeft over wat taal is (en later nuttig). Het is onethisch, maar zou je tijdens de zwangerschap veel luide achterstevorentaal laten klinken in de buurt van de moeder en helemaal als die moeder zelf achterstevoren kan praten, ook al heeft dat nul nut, dan zou de test met de baby andersom uitpakken.
Uit dat er zoveel verschillende grammatica’s zijn geeft inderdaad aan dat daar niet veel aangeboren kan zijn. Erger nog: eigenlijk volgt eruit dat taal niet zoveel voorstelt. Wat wel aan de hand is, is dat als ergens heel veel van is, dat het dan handig is om er structuren in aan te brengen. Van taal is er zeker heel veel, tienduizend woorden en een hele zwik verschillende verbanden daartussen, daar heeft men ooit wat structuur in aangebracht en dat pikt een volgende generatie op. Bij geschreven taal is het helemaal handig om nauwkeurig de grammatica van jouw taal te volgen, want intonatie en lichaamstaal ontbreken. Maar kijk naar het ontzaglijke aantal uitzonderingen, onregelmatigheden enzovoorts en de conclusie moet wel zijn dat grammatica eigenlijk een willekeurig zooitje regels is. Wel nuttig, want luister naar het enorme aantal onaffe zinnen en zelfs ongrammaticale zinnen dat je om je heen hoort en tóch begrijpt.
Het is natuurlijk wel aangeboren om erg veel op je soortgenoten te letten en dat gaat voor de geboorte al beginnen.
Bij alles waar er veel van is breng je wat structuur aan. Een goede vogelaar kent duizenden geluiden, alleen de koolmees maakt er al een honderdtal. Je deelt ze in in kort of lang, dalende of stijgende liedjes, schril of vloeiend, luid of zacht, scherp (met veel boventonen) of rond (met weinig boventonen), enzovoort. Uit dat je dit kunt volgt natuurlijk niet dat er een aangeboren iets in de hersenen is om vogelgeluiden te kunnen herkennen. Maar het gaat de mogelijkheden van de hersenen niet te boven en het stelt ook niet zo heel veel voor, want het werkt snel en efficiënt. Hoor je een bepaald geluid, dan weet je dat het een Afrikaanse zeearend is en dan weet je dat je in Afrika bent, of dat je in de buurt van een dierentuin bent, of dat ik in de buurt ben, want ik maak dat geluid als ik iets heel bijzonders aantref in de natuur.
De tabula rasa klopt in die zin dat je uiteraard met nul woorden, nul woordsoorten en nul structuur begint. Het vullen van de tabula zou dan inductief gebeuren, maar daar heb ik een duidelijke mening over: inductie bestaat niet, leren via inductie is onmogelijk. Het enige wat onze hersenen (en alle andere hersenen) kunnen is modellen maken. In het geval van taal is het: situatie plus reeks klanken geeft volgende situatie. Dat slaan we uiterst compact op, dus ook heel erg versimpeld, maar dat is efficiënt. En dus bruikbaar. Eerst is het: hongergevoel plus blèren leidt tot borstvoeding, later wordt dat hongergevoel plus ‘zoudet gij de soepterrine even door willen geven’ leidt tot soep lepelen. (‘Zoudet’ snapt de spellingchecker niet!)
Dat constructivisme lijkt me geen middenweg. Het is een model van hoe kennisopbouw gaat. Net zei ik al dat volgens mij hersenen uitsluitend modellen kunnen maken en daar voeg ik aan toe dat we uitsluitend de axiomatische methode hanteren. Daar kan ik je uren over doorzagen en deze reactie is al zo lang.
Tenslotte: CHATgpt vult zich via inductie. Dat levert nooit echt begrijpen op.