Over de wiskunde van woordladders
Dankzij de stukjes van Rutger Kiezebrink op de Taalkalender van Onze Taal ben ik de laatste tijd geïntrigeerd geraakt door woordladders. Hoe kom je van vlo naar mug? Men neme het woord vlo, verandere één letter en men heeft vla. Daarvan maak je via, en vis, mis, mus, om uit te komen bij mug. Van bloedzuigend insect naar zoemend insect beland, via een zuivelproduct en een kerkdienst heen. Het spelletje werd in de negentiende eeuw bedacht door de Britse schrijver-wiskundige Lewis Carroll. En dankzij Kiezebrink is de kunst van de woordladderconstructie in het Nederlands op grote hoogte geraakt. (Probeer nu van mug naar tor te komen, en dan van tor terug naar vlo).
Het spelletje zegt ook iets over wat wel de dichtheid van de woordenschat wordt genoemd. Dat gaat over hoeveel van de beschikbare ruimte de woordenschat gebruikt. Het aantal mogelijke drieletterige woorden is aaa, aab, aba, abb,… en zo verder tot aan zzz. Dat geeft een ruimte van 26x26x26 mogelijke woorden, iets meer dan 17.000. De daadwerkelijke drieletterige woorden van het Nederlands nemen ongeveer 10% van die ruimte in beslag (het zijn er ongeveer 1700). Hoe langer de woorden worden, hoe minder dicht de ruimte. Bij 5 letters zijn er al 26⁵ ≈ 12 miljoen mogelijkheden voor slechts 9.825 woorden: 0,08%. Bij 10 letters is de dichtheid gedaald tot ruwweg 0,000000003%. Het is daardoor veel gemakkelijker om woordladder te spelen met drieletterige woorden, ook omdat de beschikbare woorden nog veel meer op elkaar lijken dan bij een willekeurige verdeling zou blijken.
Wat zou er gebeuren als je dat spelletje niet voor twee woorden speelt, maar voor de hele Nederlandse woordenschat? Dat is een vraag van een vakgebied dat in Nederland ernstig verwaarloosd wordt – de wiskundige taalkunde. Je neemt een woordenlijst en je verbindt elk paar woorden dat op precies één letter verschilt.
Ik gebruikte de de gratis woordenlijst van OpenTaal met ruim vierhonderdduizend woorden. Dat is heel ruim. Er zitten bijvoorbeeld ook verbogen vormen in (mooie naast mooi, loopt naast lopen), wat op zich goed is, maar ook heen heleboel namen (Loes, Unox), afkortingen (btw) en andere zaken die je misschien niet per se woorden zou noemen. Maar omdat dit nu eenmaal de beste vrij toegankelijke lijst van het Nederlands is, heb ik hem toch maar gebruikt.
Weefsel
Als je in zo’n woordenlijst een lijntje zet tussen alle woorden die een letter met elkaar verbonden zijn, krijg je een gigantisch netwerk, een graaf in de wiskundige terminologie. De vraag is nu: hoe ziet dat netwerk eruit? Het antwoord hangt af van hoeveel letters je woorden hebben.
Bij tweeletterwoorden vormen alle 262 woorden uit de lijst één groot netwerk. Elk woord is via een woordladder bereikbaar vanuit elk ander woord. Óf is vier stappen verwijderd van já (geaccentueerde letters doen ook mee als aparte letters), en dat is het verste dat je kunt komen. We noemen dat de diameter van de graaf. De gemiddelde afstand is veel kleiner. Het is een hecht, dicht verweven weefsel — elk woord heeft gemiddeld 21 buren.
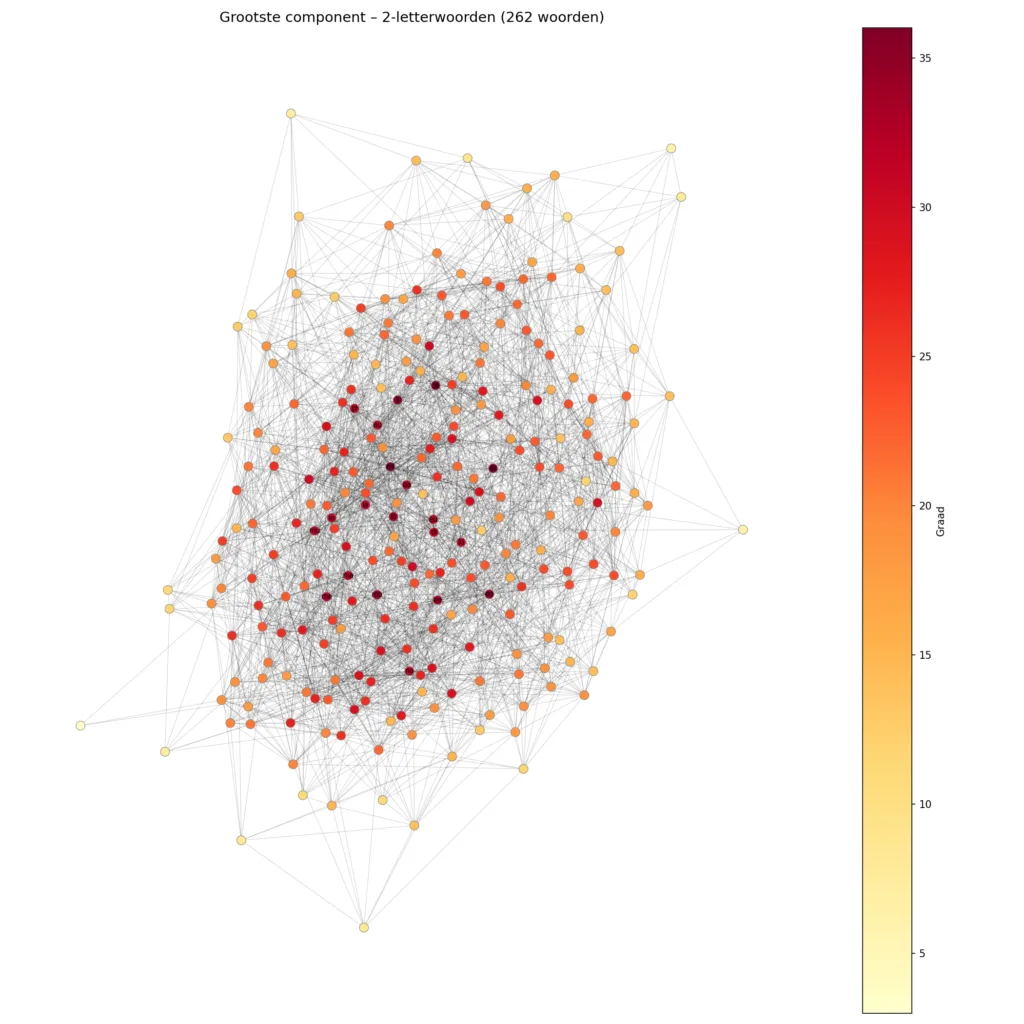
Sommige woorden zitten hier wat dieper ingebed in de figuur dan andere, en hebben een donkerder kleur. Dat geeft aan hoeveel buren een woord heeft. Het woord ei heeft bijvoorbeeld 36 buren, waaronder eb, ed, el, en, mi, oi en bi. Dat zit woord zit daardoor heel diep aan in het netwerk.
Bij drieletterige woorden is het beeld nauwelijks anders: 99,8 procent van de 1703 woorden zit in één gigantische cluster. Er zijn slechts drie geïsoleerde woorden, drie kluizenaars die met geen enkel ander drielettergrepig woord verwant zijn: kwh (kilowattuur), tgv (de Franse hogesnelheidstrein) en óók.Bij dat laatste zitten de twee accenten nabuurschap in de weg, want óok of oók zijn geen woorden.
Maar dan. Bij vijf letters is nog 83 procent van de woorden via woordladders met elkaar verbonden, maar er zijn al ruim negenhonderd compleet geïsoleerde woorden — woorden die geen enkele buur hebben. Bij zes letters zakt de grootste component naar 62 procent. Bij zeven naar 36 procent. En bij acht letters stort het in: nog maar 4 procent van alle woorden zit in de grootste component.
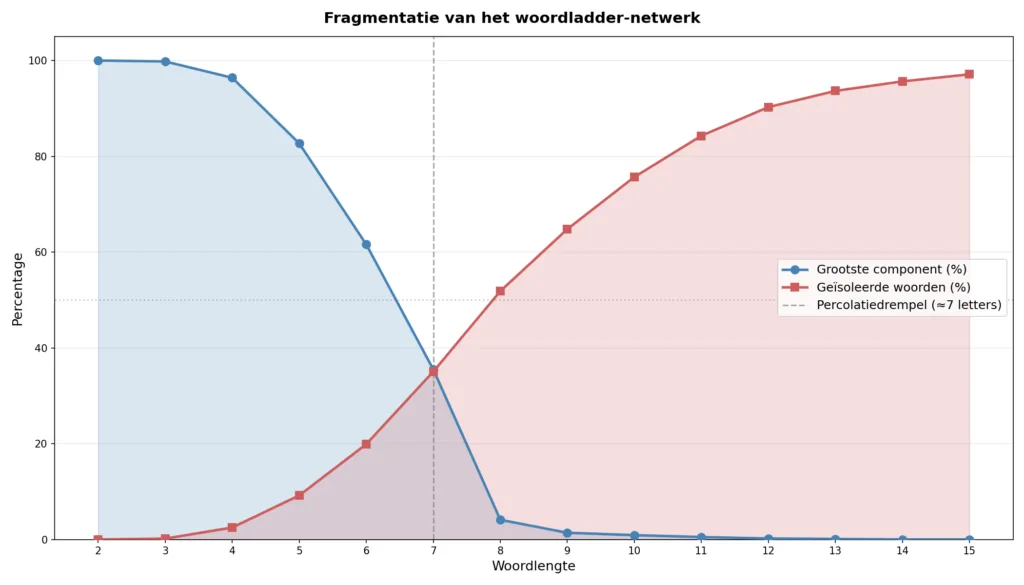
De grafiek hierboven laat dat zien. De blauwe lijn (de grootste component) en de rode lijn (de geïsoleerde woorden) kruisen elkaar rond woordlengte zeven. Rechts van dat kruispunt bestaat de woordenruimte uit een archipel van eilandjes in een gigantische oceaan, en staat de overgrote meerderheid van de woorden er alleen voor. Bij vijftien letters is 97 procent van alle woorden volledig geïsoleerd. De grootste “component” bestaat daar uit slechts vier woorden: kernvergadering, kerkvergadering, werkvergadering en werfvergadering.
Woestijn
Dit lijkt op een fenomeen dat in de natuurkunde bekendstaat als een faseverandering. In de theorie van willekeurige grafen — netwerken die ontstaan door knooppunten willekeurig met elkaar te verbinden — treedt er een abrupte overgang op wanneer het gemiddeld aantal verbindingen per knoop onder een bepaalde drempel zakt. Boven die drempel bestaat er een “reuzencomponent” die een flink deel van het hele netwerk omvat. Eronder valt het netwerk uiteen in talloze kleine fragmenten.
In onze woordladdergraaf zien we precies dit patroon. De gemiddelde graad (het gemiddeld aantal buren per woord) zakt bij acht letters onder 1. En inderdaad: de reuzencomponent, die bij zeven letters nog 36 procent van alle woorden omvat, is bij acht letters ineens gedecimeerd tot 4 procent.
Die drempel vertelt iets over hoe de woordenschat van het Nederlands — en vermoedelijk van elke natuurlijke taal — in elkaar zit. Bij drie letters is de woordruimte is goed gevuld; de wereld van de drieletterige woorden is als een stad waar bijna elk perceel bebouwd is. Je kunt gemakkelijk van huis naar huis lopen. Bij tien letters zijn er 26¹⁰ mogelijke combinaties — ruwweg honderdduizend miljard — maar daarvan zijn er slechts 45.000 echte woorden. Dat is een dichtheid van drie honderdste van een miljardste procent. De woordruimte is een woestijn geworden.
Langste route
Misschien het interessantste resultaat is de diameter van het netwerk: de langste kortste woordladder, het maximale aantal stappen dat je nodig hebt om via de kortst mogelijke route van het ene woord bij het andere te komen.
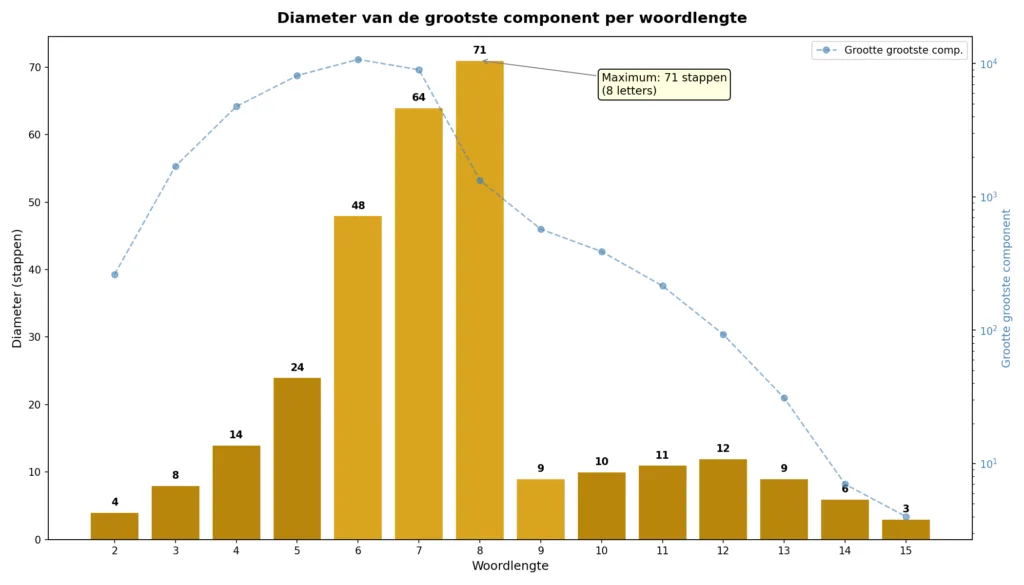
De diameter groeit aanvankelijk snel, van 4 stappen bij twee letters naar 24 bij vijf. Het absolute record ligt bij acht letters: daar is de diameter naar 71 stappen:
vernaait → verwaait → verwaaid → verwaand → vermaand → vermaant → vermaakt → verzaakt → verzwakt → verzwikt → verkwikt → verklikt → verslikt → verstikt → verstilt → verspilt → verspild → verspeld → versperd → verspert → verseert → verweert → verwoert → verhoert → verhoedt → verhoede → verwoede → verwonde → verkonde → verkende → werkende → wekkende → rekkende → reikende → zeikende → zeilende → peilende → pellende → bellende → beleende → geleende → geleerde → gekeerde → gekeelde → geknelde → gesnelde → gestelde → gestalde → gestalte → gestapte → gestipte → geslipte → geflipte → geflapte → geklapte → gekaapte → geraapte → geraamte → geraamde → geraasde → gemaasde → gemaande → gebaande → gebrande → gebralde → gebrilde → gebuilde → gebuisde → gehuisde → behuisde → behuilde → bevuilde
Het pad loopt van vernaait naar bevuilde, en het reist door het hele landschap van Nederlandse werkwoordsvormen — eerst door de ver--woorden (verwaait, verwaand, vermaakt, verzaakt, verzwakt, verklikt, verstikt, verspilt…), dan door een overgangsgebied van tegenwoordige deelwoorden (werkende, reikende, zeilende, bellende…) en ten slotte door de ge--woorden (geleerde, gekeerde, gestelde, gestalte, gekaapte, geraamte, gebaande, gebrilde, bevuilde). Grappig is dat de tweede letter op dat lange pad nooit veranderd. Dat betekent dat de andere letters gemiddeld tien keer veranderen voor ze bij het eindpunt komen.
Maar daarna daalt de diameter snel. Dat is het gevolg van de faseverandering: bij langere woorden is het netwerk zo sterk gefragmenteerd dat er simpelweg geen lange paden meer bestaan. De eilandjes zijn te klein. Bij vijftien letters is de diameter nog maar drie stappen.
Het maximum bij acht letters is dus een sweet spot, een punt waar twee tegengestelde krachten in evenwicht zijn: het netwerk is nog net groot genoeg om lange paden te bevatten, maar al ijl genoeg dat woorden ver uit elkaar kunnen liggen. Het is het punt van maximale spanning.
Wat dit vertelt
Je kunt deze resultaten op verschillende manieren lezen. Als puzzel — en dan zijn de paden zelf het leukst, de 71 stappen van vernaait naar bevuilde, als een wandeling door de woordenschat. Als wiskundig object — en dan is de faseverandering het meest opvallend, de scherpte waarmee het netwerk instort rond woordlengte acht.
Taalkundig kun je er ook wel iets uit leren over de structuur van de woordenschat. Bij elf letters zijn de componenten die overblijven geen willekeurige verzamelingen woorden. Het zijn families: ondervoeden → ondervonden → ondervinden → ondervingen. Of straatnamen: westerstraat → oosterstraat → kosterstraat → potterstraat. De morfologie — het systeem van voor- en achtervoegsels, vervoegingen en verbuigingen waarmee we van woorden andere woorden maken — houdt woorden bij elkaar die anders allang geïsoleerd zouden zijn. Als de fonologie de lijm is die korte woorden aan elkaar plakt (er zijn nu eenmaal maar zo veel drielettercombinaties), dan is de morfologie het touw dat langere woorden in kleine groepjes samenhoudt wanneer die lijm niet meer werkt.
Er is vast veel meer te ontdekken. Wat gebeurt er als je niet alleen lettervervanging toestaat maar ook het invoegen en verwijderen van letters, zodat woorden van verschillende lengte met elkaar verbonden kunnen raken? Hoe verhouden de Nederlandse netwerken zich tot die van het Engels of het Duits? Of van talen met veel langere woorden, en veel meer morfologie, zoals het Fins? Is de percolatiedrempel specifiek voor het Nederlands of vinden we hem elders ook? En wat zegt de positie van die drempel over de taalkundige structuur van een taal?
Eens zien welke woorden zich daar nog laten bereiken.
Een aantal scripts om met woordenladders te werken, staat hier.
Dank voor dit artikel en het script. Is er ook iets te doen met zinnen die uit woordladders bestaan (‘Eet het met Tim’), vraag ik mij af. Heeft Battus dat al gedaan? En zou je dit ook met fonetische woordladders kunnen doen?
Wat een interessant idee! Je voorbeeld klopt niet helemaal (verbeterde versie: ‘Eet het met Mat’, maar die heeft nog het probleem dat de eerste drie woorden allemaal van elkaar verschillen in de eerste letter, dat is nog niet optimaal. Leefde Battus nog maar! Die zou ze vinden. Het beste dat ik kan bedenken: ‘Moren boren boven bomen’.
Het lijkt me principieel niet heel lastig om dit te doen met fonetische transcripties, zoals te vinden in CELEX. Voor de wiskundige doelen is het wel fijn om een absurd groot bestand te hebben zoals OpenTaal, waarin heel liberaal wordt omgegaan met het begrip ‘woord’. En zoiets bestaat niet in fonetische transcriptie.